로그 시스템 개선기 (서버리스를 곁들인)
들어가며
무언가를 처음부터 구축하는 건 언제나 즐겁고 의미 있는 일인 것 같습니다. 저희 회사의 로그 시스템은 그동안 문자열 형태로 CloudWatch에 무분별하게 쌓이고 있었고, 이로 인해 로그가 방치되고 검색이 매우 어렵다는 점이 가장 큰 문제였습니다. 이를 해결하기 위해 S3 + Athena + Kinesis Firehose를 활용해 로그를 실시간으로 S3에 적재하는 시스템을 구축하기로 했습니다.
로그 시스템 개선 계획
우선, 처음에 어떤 방식으로 로그 시스템을 개선하고자 했는지 공유드리겠습니다. 물론 해당 방법은 잘 되지 못했는데, 후에 서술할 예정입니다.
레거시 로그 처리
먼저 현재 CloudWatch에 쌓여있는 레거시 로그를 정리해야 합니다. 1개월 이전의 오래된 로그는 아카이빙 용도로 S3에 export하고, 최근 1개월치 로그는 CloudWatch에 그대로 유지합니다. S3로 이관이 완료되면 1개월 이전 로그는 CloudWatch에서 삭제하고, 이후 CloudWatch Retention Policy를 1개월로 설정하여 자동으로 로그가 삭제되도록 구성합니다.
처음 설계한 로그 적재 방식
앞으로 쌓일 새로운 로그는 다음과 같이 처리됩니다. 모든 로그는 애플리케이션과 시스템에서 Kinesis Data Firehose로 전송되고, Firehose에서 Parquet 형식으로 변환 및 자동 GZIP 압축을 거쳐 S3에 저장됩니다. 이렇게 저장된 로그는 Athena를 통해 쿼리할 수 있습니다.
에러 로그의 경우 CloudWatch Logs에 별도로 보관되며 1주일 뒤 자동 삭제됩니다. 참고로 Firehose는 초당 1000건 제한이 있지만, 우선 적용한 뒤 필요시 제한 완화 및 배치 전송을 고려할 예정입니다.
로그 적재 전략 선택
로그 적재 전략에 대해 두 가지 선택지를 고민했습니다.
옵션 1: 모든 로그를 Firehose로 전송
필요한 작업
- 의미 없는 API 로그를 필터링하도록 애플리케이션 수정
- S3 버킷 Lifecycle 정책 설정으로 오래된 로그를 Archive 계층으로 이동
비용
- Firehose 비용 + S3 스토리지 비용 증가
- 예상: 월 $1~5 정도로 미미한 수준
장점
- 로그를 장기간 저렴하게 보관 가능
- GET 요청 로그도 포함되어 사용자 행동 분석 가능
옵션 2: POST 등 중요한 로그만 적재
필요한 작업
- GET 페이지에서 POST 요청하는 API(예: prod/facade)를 GET으로 변경하거나 로그 필터링
비용
- Firehose + S3 비용 절감
- CloudWatch 로그 보관 기간을 1개월로 연장 가능
단점
- GET 요청 로그는 보관 기간 이후 영구 삭제
- 사용자 행동 분석 제한
장점
- CS 문의는 대부분 1개월 이내 로그만 필요하므로 효율적
이 둘 중에서는 첫번째 옵션을 택하였습니다. POST 요청 말고도 GET 요청을 통해서, 행동 패턴을 알 수도 있었고, GET에서도 중요한 응답을 주는 경우가 많았기 때문입니다.
S3 파티셔닝 전략
데이터를 저장할 때 ‘연/월/일’로 나누어 저장하는 방식은 직관적이지만 비효율적입니다. 대신 ISO 8601 형식 기반의 단일 날짜 파티션 방식을 사용하는 것이 좋습니다.
s3://bucket/data/dt=2025-01-01/events.parquet
이 방식의 장점
- ISO 형식(YYYY-MM-DD)은 문자열 정렬 시 자연스럽게 날짜 순서가 유지됩니다
WHERE dt >= '2025-01-01' AND dt <= '2025-02-10'같이 쿼리 가독성이 높아집니다- 필요한 날짜만 정확히 스캔하므로 파티션 프루닝이 효율적입니다
- 관리해야 할 파티션 수가 줄어들고 S3 API 호출도 최소화됩니다
연도별 데이터만 조회할 때 쿼리가 약간 길어질 수 있지만, 대부분의 쿼리가 빨라진다는 이점이 훨씬 큽니다.
기대 효과
이렇게 개선함으로써 얻는 기대 효과는 여러 가지입니다.
그중에서도 가장 기대되는 효과는 SQL 쿼리로 로그 검색이 가능해진다는 것입니다. 전의 구조에서는 CloudWatch의 log insight에서, 특정 문법을 사용해서 로그를 검색해야 했습니다. 하지만, 이마저 로그가 구조화가 되어있지 않다면 매우매우 검색이 어려워집니다.
하지만 개선된 구조라면 Athena table, 즉 Glue Catalog에 정의되어있는 구조화 된 데이터들을 친숙한 SQL로 검색할 수 있다는 것이 가장 큰 장점입니다. 이를 통해서 다른 이해 관계자들도 SQL만 알 수 있다면 로그를 찾아볼 수 있고, 집계도 내는 것이 용이해집니다. 덩달이 자연스럽게 CS 처리 속도도 상승되겠죠!
개발 착수
실보다는 득이 매우 많기 때문에, 과감하게 계획한 바를 실행했습니다.
1단계: 로그 구조화
우선적으로 구조화되지 않은 채로 적재되고 있었던 로그들을 JSON 형식으로 구조화하여 stdout으로 출력하도록 애플리케이션을 수정했습니다. 기존에는 단순 문자열 형태였던 로그를 다음과 같은 구조화된 JSON 포맷으로 변경했습니다.
{
"timestamp": "2025-12-03T10:15:30Z",
"level": "INFO",
"request_id": "abc-123",
"method": "POST",
"path": "/api/users",
"status_code": 200,
"response_time": 45
}
또, 기존 로그에는 포함되지 않았던 response_code 라던가, status_code, resposne_time 등 응답에 대한 로그도 추가시켜 추적과 집계에 더 용이하도록 로그를 구성하였습니다.
2단계: 불필요한 로그 필터링
모두에게 호출되는 의미 없는 GET API들(헬스체크, 정적 리소스 등)은 stdout되지 않도록 필터링을 추가했습니다. 이를 통해 로그 볼륨을 줄이고 Firehose 비용을 절감할 수 있을 뿐더러 추적이 더 쉬워졌습니다.
3단계: Glue Catalog 테이블 생성
Athena에서 CREATE TABLE DDL을 사용하여 로그 구조를 따라 테이블을 생성했습니다. Athena에서 테이블을 생성하면 자동으로 AWS Glue Data Catalog에 메타데이터가 등록됩니다.
CREATE EXTERNAL TABLE server_logs (
timestamp TIMESTAMP,
level STRING,
request_id STRING,
method STRING,
path STRING,
status_code INT,
response_time INT
)
PARTITIONED BY (dt STRING)
STORED AS PARQUET
LOCATION 's3://my-bucket/data/'
4단계: Kinesis Firehose 설정

Glue Catalog에 테이블이 등록되면, Kinesis Firehose에서 이 테이블 스키마를 참조하여 데이터를 변환할 수 있습니다. Firehose의 데이터 변환 설정에서 Glue Catalog의 테이블을 지정하면, 들어오는 JSON 로그를 자동으로 Parquet 형식으로 변환하여 S3에 저장합니다.
firehose를 생성할 때, 버퍼 크기와 버퍼 시간을 정할 수 있는데, 비용에 많은 영향을 주는 옵션입니다. 이는 후에 따로 포스트를 올릴 예정이에요.
이렇게 설정하면 Application → Firehose → S3 → Athena로 이어지는 완벽한 로그 파이프라인이 구축됩니다.
트러블 슈팅
레이턴시 이슈 발생
구현 과정에서 예상치 못한 문제가 발생했습니다.
- FastAPI 라우터에서 aioboto3 + asyncio를 사용해 비동기로 Firehose에 로그를 전송해도 평균 API latency가 200~800ms 증가
- Firehose → S3로 보내는 과정을 완전히 분리된 비동기 방식으로 처리해야 함
Latency가 충격적으로 늘어나서 여러 가지 방안을 찾아보았습니다. Fluent Bit을 따로 컨테이너에 띄워서 로그 파일을 비동기로 Firehose에 전송하는 방법도 존재했고, 아니면 포기하고 전처럼 CloudWatch만 사용하도록 롤백하는 방법도 있습니다.
하지만 포기하지 않고 계속 찾아보던 중 AWS에서 제공하는 기능인 구독 필터를 발견해서 테스트해보기로 했습니다.
Subscription Filter 활용
바로 CloudWatch의 기본 기능인 Subscription Filter(구독 필터)을 활용하는 방법입니다.
최종 아키텍처
stdout → CloudWatch Logs → Subscription Filter → Firehose → S3 → Athena
동작 방식은 다음과 같습니다.
- 모든 로그는 CloudWatch에 우선 적재
- Subscription Filter를 통해 로그를 Firehose로 전송
- 패턴을 지정해 특정 로그만 선택적으로 전송 가능
- Firehose가 로그를 Parquet 형식으로 변환 후 파티션으로 저장
- 예:
s3://serverlog/data/dt=2025-12-03/
- 예:
- Athena로 SQL 쿼리 검색 가능
해당 방법은 기존 처럼 CloudWatch Logs에 로그들을 우선적으로 적제를 하기 때문에, 비용적인 측면에서는 개선을 기대할 수 없습니다. 하지만 retention policy를 통해서 CloudWatch Logs에 오랜 기간 로그들이 쌓여있지 않도록 조정하면 어느 정도 커버가 가능합니다.
트러블 슈팅
구독필터를 사용해서 다시 프로젝트를 이어 갔는데, 이 과정에서 여러 문제가 발생해서 어려움을 겪었습니다.
로그를 압축해서 보내는 문제
Encountered malformed JSON. Illegal character ((CTRL-CHAR, code 31)): only regular white space (\r, \n, \t) is allowed between tokens at [Source: REDACTED (
StreamReadFeature.INCLUDE_SOURCE_IN_LOCATIONdisabled); line: 1, column: 2]
CloudWatch Logs는 기본적으로 Firehose에 로그를 전송할 때 gz 형식으로 압축하여 전송합니다. 이 때문에 헤더에 불필요한 바이트가 포함되어 위와 같은 에러가 발생합니다.
처음에는 Firehose 데이터 변환 파트에 람다를 추가해야 하나 고민했는데, AWS 공식 문서를 통해서 이를 해결했습니다.
해결 방법
Turn on decompression옵션 활성화- CloudWatch → Firehose로 로그 전송 시 자동으로 압축 해제
새 줄 구분자 추가옵션 활성화- 로그 레코드를 제대로 분리하기 위해 필수
Firehose 설정
- 출력 형식: Apache Parquet
- 접두사:
data/dt=!{timestamp:yyyy-MM-dd}/
모든 필드가 null로 저장되는 문제
드디어 S3에 Parquet 파일이 생성되었습니다. 하지만 파일을 열어보니 모든 필드가 null로 저장되어 있었습니다.
{"timestamp":null,"level":null,"request_id":null, …,"error_traceback":null}
원인
Turn on message extraction 옵션을 활성화하지 않았기 때문입니다.
CloudWatch에서 Firehose로 전송되는 로그는 압축 해제 시 다음과 같은 메타데이터를 포함합니다.
{
"messageType": "DATA_MESSAGE",
"owner": "831576238138",
"logGroup": "/ec2/tmm-dev-api",
"logEvents": [
{
"id": "...",
"timestamp": 1234567890000,
"message": "{\"timestamp\":\"2025-12-03...\",\"level\":\"INFO\",...}"
}
]
}
해결 방법
Turn on message extraction 옵션을 활성화하면 message 필드만 추출합니다. 이 옵션을 활성화하지 않으면 메타데이터가 모두 Firehose로 전송되어 Glue Catalog 스키마와 일치하지 않게 되고, 결과적으로 모든 필드가 null로 저장됩니다.
그 외 주의사항
Glue Catalog 스키마 변경 시점 Firehose의 버퍼 기간 중간에 Glue Catalog를 변경하면 하나의 Parquet 파일 내에서 데이터 타입이 섞이게 됩니다. 이 경우 Athena 쿼리 실행 시 타입 불일치 에러가 발생하므로 주의해야 합니다.
Timestamp 쿼리 방법
Glue의 timestamp 타입을 쿼리할 때는 값 앞에 timestamp 키워드를 붙여야 합니다.
WHERE timestamp_column = timestamp '2025-12-03 00:00:00'
결과 및 실제 비용 확인
쿼리 조회
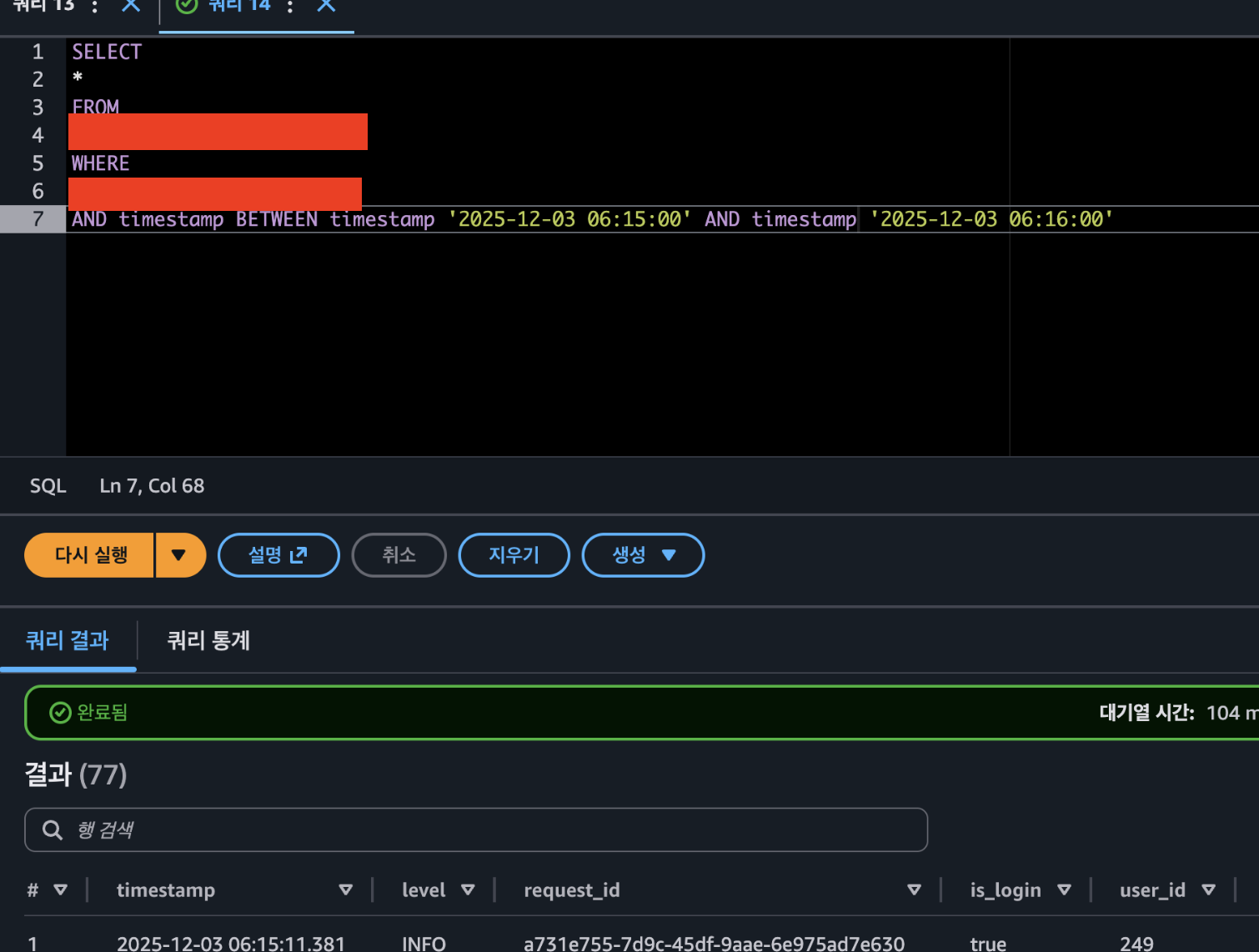
이미지와 같이 SQL로 쿼리를 검색할 수도 있고, 주기마다 집계쿼리를 통해서 API에 대한 통계도 내볼 수 있습니다. 더 나아가서 AWS의 Amazon Quick Suite라던가, Quicksight, Apache Superset 등으로 시각화까지 확장하여 쓸 수 있습니다.
비용
2025-12-14, Kinesis Firehose, Decompression: 0.47GB → $0.0019
2025-12-14, Athena, DataScanned: 0.00001TB → $0.00005
물론 로그의 양따라 달라지겠지만, Kinesis Firehose와 Athena는 생각보다 매우 저렴합니다. 이는 해당 아키텍처에서 사용된 서비스 모두 서버리스 서비스이기 때문입니다. 다른 SaaS와 다르게 로그 검색을 하지 않으면 S3 저장 비용만 나가니, 정말 합리적입니다. 물론 모니터링 툴을 비롯해 성능이 아주 훌륭한 로그 서비스들은 아주 다양합니다. 하지만 저희 회사의 규모와 더불어 용도에 맞는 솔루션을 찾고 이를 구축했다는 데 아주 큰 보람을 느끼고 있습니다.
후에 로그가 더 많아진다면, fluent bit로 마이그레이션을 도전해 볼 예정입니다. 긴 글 읽어주셔서 감사합니다!