확장성과 재사용성을 고려한 lambda 기반 llm 시스템 구축기

LLM을 다양한 곳에 사용해보자라는 사내 요구 사항이 점차 늘게 되면서, 확장성과 재사용성을 고려한 Lambda 기반 LLM 시스템을 개발하였습니다. 이 시스템의 첫 번째 활용 사례로 고객 문의를 요약하고 감정 표현을 정제하는 기능을 구현한 경험을 공유하겠습니다.
설계
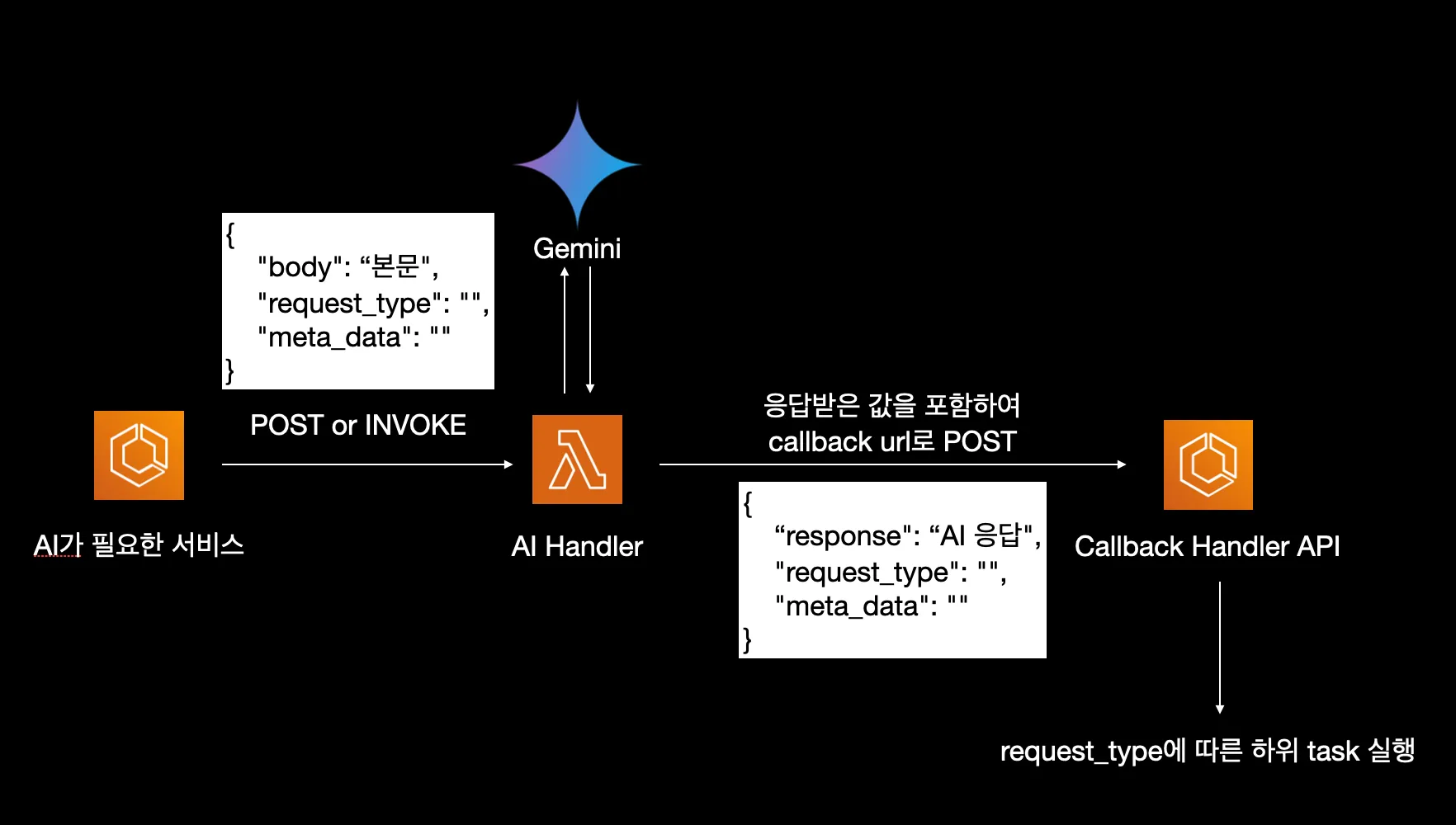
가장 중요한 것은 다양한 곳에서 LLM을 활용할 수 있는 범용적인 아키텍처를 만드는 것이었습니다. 단순히 특정 용도에만 국한되지 않고, 여러 비즈니스 요구사항에 유연하게 대응할 수 있는 아키텍처를 목표로 했습니다.
LLM 처리를 Lambda로 분리
우선 처리 시간이 긴 LLM 처리는 운영 서버와 별도로 분리하는 것이 좋다고 생각을 하였습니다. 운영 서버와 별도의 스케일링으로 요청을 처리하고, 운영 서버의 리소스를 잡아 먹지 않기 위해 Lambda로 분리를 하는 판단을 했습니다.
또한 LLM 관련 무거운 라이브러리와 의존성을 운영 서버와 분리를 할 수 있고, AWS 서비스 내에서 다양한 서비스에서도 호출하여 활용할 수 있게 만들었습니다.
단일 책임 원칙
또한, 확장성을 위해서는 단일 책임 원칙 을 지키는 것이 중요했는데요, Lambda 함수에 너무 많은 책임을 부여하지 않기 위해 다음과 같이 설계하였습니다.
- 람다는 LLM 요청을 처리하고 응답을 생성할 뿐, 다른 비지니스 로직을 처리하지 않는다.
- 비지니스 로직(DB 저장과 이메일 발송과 같은 태스크)은 운영 서버에서 처리한다.
따라서 람다는 LLM만 처리하고, 비지니스 로직을 처리하기 위해 운영 서버의 callback URL을 호출하는 방식으로 책임을 분리하였습니다.
콜백 패턴 적용
앞서 서술했듯이, LLM 처리 완료 후 요청 시 받았던 metadata와 함께 callback URL로 POST 요청을 보내는 방식을 채택했습니다.
이 방식을 통해서 몇 가지 이점이 있었는데요, 기존 운영 서버의 로직을 재활용 수 있었고 Lambda의 복잡도를 최소화 하였습니다. 만약 이메일 전송 및 DB 작업도 람다에서 진행되었다면 Lambda는 매우 무거워지고, 비지니스 로직이 변경될 때 람다 또한 수정해야하기 때문에 유지보수에 불리해집니다.
이렇게 callback 패턴을 사용하면 느슨한 결합을 유지할 수 있기 때문에 유지보수성이 향상되는 이점이 있습니다. 만약 새로운 곳에 LLM이 활용되어야 하는 요구사항이 생기면 타입에 맞는 promt를 추가하고, callback api를 생성하면 작업이 끝입니다.
LLM 서비스 추상화
현재는 AWS Bedrock 대신 Google Gemini 2.0을 선택했습니다. 비용 대비 성능을 고려한 결정이었는데, 실제로 성능도 만족스럽게 나왔습니다.
하지만 향후 다른 LLM 서비스로 쉽게 전환할 수 있도록 LLM Service를 interface화하여 다음과 같이 추상화 계층을 구현했습니다.
class AIServiceInterface(ABC):
@abstractmethod
def generate_response(self, prompt: str) -> Optional[str]:
pass
def handle_ai_request(ai_request: AiRequest, ai_service: AIServiceInterface) -> AiResponse:
prompt = make_promt(ai_request.body)
response: Optional[str] = ai_service.generate_response(prompt)
post_callback(response)
실제 AI 서비스는 handle_ai_request 외부에서 생성되어 ai_service라는 파라미터로 전달받습니다.
ai_service = GeminiService()
response = handle_ai_request(ai_request, ai_service)
적용 사례
첫 번째 적용 사례는 고객 문의를 요약 및 정제하는 곳에 활용하였습니다. 정형화 되지 않은 고객 문의를 정형화 해주고, 스트레스를 유발할 수 있는 어투나 표현들을 순화시켜 운영팀의 업무 부담을 크게 줄일 수 있을 것이라는 기대를 하였습니다.
callback API에서는 정제된 고객 문의를 받고 이를 고객 문의 DB에 저장시킨 후, slack에 AI 요약이 포함된 고객 문의를 전송시켜주는 로직을 구현하였습니다.
예시:

기술적 고민
Lambda에서 callback URL로 POST 요청을 보낼 때 기존 requests 라이브러리를 사용하면 blocking 방식으로 작동해 Lambda 함수 종료가 지연됩니다. 현재는 문제없지만, 향후 Function URL로 API처럼 사용할 경우 응답 시간이 길어지기 때문에 사용자 경험이 저하될 수 있습니다.
그래서 두 가지를 해결법을 고민하였습니다.
requests-futures 라이브러리
# requests-futures를 사용한 비동기 요청
from requests_futures.sessions import FuturesSession
session = FuturesSession()
future = session.post(callback_url, json=data)
해당 라이브러리는 스레드 풀을 사용해 병렬로 요청을 실행하는 방식입니다. 하지만 Lambda 함수가 종료되면 스레드 풀도 함께 종료되어 비동기 요청들이 완료되지 못하고 중단되는 문제가 발생했습니다.
requests의 짧은 timeout 설정
callback URL에 POST 요청을 하는 것은 “fire and forget” 방식으로 처리해도 됩니다. 즉 응답을 받을 필요가 없기 때문에 “의도적으로 POST 요청에 짧은 timeout을 설정하면 어떨까?” 라는 생각을 떠올렸습니다.
try:
requests.post(callback_url, json=data, timeout=0.1)
except requests.exceptions.Timeout:
# 의도된 timeout이므로 무시
pass
except Exception as e:
# 다른 예외는 로깅 후 처리
logger.error(f"Callback request failed: {e}")
raise
이렇게 하면 요청을 보낸 뒤 0.1초 내에 Lambda 함수가 종료되고, POST 요청도 정상적으로 동작이 됩니다. 비록 callback 서버에 응답을 확인할 수 없는 단점이 존재하지만, 간단하고 안정적으로 구현이 가능하다는 장점이 있습니다. 그래서 저는 최종적으로 이 방법을 택하였습니다.
마무리
LLM을 활용해서 운영팀의 업무 부담을 줄여주었다는 것에 큰 보람을 느꼈고, 여기에서 멈추지 않고 다양한 곳에 해당 시스템을 활용할 생각입니다.
개선점도 명확한데요, 현재는 Gemini API를 사용하기 때문에 google 모델 서버와 강한 결합이 되어있습니다. 때문에 다른 벤더의 AI 서비스도 추가로 사용해서 안정적으로 고가용성을 보장하는 아키텍처로 개선을 진행할 예정입니다. (bedrock을 사용하는 것을 목표로..)