Dynamodb의 키 모델링과 파티셔닝
DynamoDB 키 모델링
- GSI는 최종적으로 일관된 읽기만 가능하고, LSI는 강력하게 일관된 읽기도 가능
- GSI를 추가 attribute와 inverted key를 통해서 조회를 할 수 있게 도와줌
- partition key와 sorted key를 카테고리#카테고리#카테고리로 만들어서 begins with를 함
- partition key를 query할 때는 equal 조건만 사용할 수 있고, sorted key만 begins_with, between를 사용할 수 있음
- data 컬럼을 둬서 GSI 설정에 대비한다. GSI-2 의 예시처럼 사용할 수 있다.
- 밑은 이해가 가지 않았던 부분이다.
SUBSCRIBE / SUBSCRIBE_USER

이번엔 각 서비스 별 구독 정보를 담고 있는 SUBSCRIBE 엔티티와 유저가 구독한 정보를 담고 있는 SUBSCRIBE_USER 엔티티입니다.
Index : GSI-1 (inverted index)
- PK = SK
- SK = PK
- Query
- select * from SUBSCRIBE where pk = SUBSCRIBE# and sk = begin_withs(SUBSCIRBE#service)
SUBSCIRBE 엔티티의 Access Pattern이 findSubscribeByServiceAndContentType 인 것을 확인할 수 있습니다. SUBSCRIBE#service#contentType#contentOriginId를 PK로 가지고 있기 때문에 GSI(inverted index)를 이용해서 GSI-PK엔 테이블의 SK를 SUBSCRIBE#로 Equal 연산하고 GSI-SK엔 테이블의 PK를 begin_withs(SUBSCRIBE#service#contentType) 연산하여 원하는 service, contentType 별 계층 데이터를 접근할 수 있습니다.
Index : GSI-2
- PK = data
- SK = SK
- Query
- select * from SUBSCRIBE_USER where pk = SUBSCRIBE_USER and sk = begin_withs(SUBSCIRBE#service)
SUBSCRIBE_USER 엔티티의 Access Pattern이 findUserBySubscribeService 이므로 한 서비스를 구독하는 유저 리스트를 조회해야합니다. 그렇게 하기 위해선 GSI를 이용하여 data에 SUBSCRIBE_USER를 적재하고 SK에 SUBSCRIBE#service#contentType#contentOriginId를 적재하여 계층 데이터를 접근할 수 있습니다. GSI-PK엔 data 속성을 SUBSCRIBE_USER를 Equal 연산하고 GSI-SK로 테이블의 SK를 begin_withs(SUBSCRIBE#service) 연산하여 SUBSCRIBE 엔티티와 마찬가지로 원하는 service, contentType 별 계층 데이터를 접근할 수 있습니다.
sk에 SUBSCRIBE#나 data의 SUBSCRIBE USER 처럼 의미 없는 데이터를 넣는 이유?
- 저렇게 하면 GSI를 inverted key로 설정하여 추가적으로 다양한 쿼리 패턴을 효율적으로 지원
SUBSCRIBE에서는SUBSCRIBE#service#contentType#contentOriginId를 PK로 사용하여 특정 구독 정보를 찾을 수 있다.SUBSCRIBE_USER에서는 특정 유저가 어떤 것들을 구독했는지 알 수 있다.
- 핫파티션 방지를 위한 것
-
DynamoDB에서는 카디널리티가 높지 않은 파티션 키는 몇 개의 파티션만을 대상으로 하는 요청이 많을 수 있습니다. 이 이벤트는 핫 파티션을 일으킵니다. 핫 파티션은 초당 3000RCU와 1000WCU(또는 이 둘 모두의 조합)의 파티션 제한을 초과할 경우 전송률 저하를 일으킬 수 있습니다.
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-partition-key-sharding.html
- 핫 파티션이 존재하고, 이를 위해서 샤딩을 수동으로 해주어야 한다.
- 따라서 SUBSCRIBE 테이블에서, 데이터가 쌓일 때는 pk에 카디널리티가 높은
SUBSCRIBE#service#contentType#Id를 해두고, GSI의 inverted key를 통해서 범위 검색을 할 때 GSI의 sorted key로 활용한다. - 실제 데이터 적재는 기본 테이블의 설계로 되기 때문에, GSI로는 Partion key에 카디널리티가 낮은 것으로 설정해도 된다.
- GSI-2도 마찬가지로 저렇게 설계하면 데이터가 분산되어 저장되어 핫파티션 방지가 된다.
- 즉, GSI에서는 필요한 쿼리 패턴을 지원하면서도 데이터가 특정 파티션에 몰리지 않도록 설계한 것
-
DynamoDB 파티셔닝
공식문서: 테이블을 생성할 때, 테이블의 초기 상태는 ‘CREATING’입니다. 이 단계에서 DynamoDB는 프로비저닝된 처리량 요구 사항을 처리할 수 있도록 테이블에 충분한 파티션을 할당합니다.
- ‘CREATING’ 상태에서 파티션을 할당하는 것은 동적 파티셔닝 시스템의 초기 설정 단계
- 초기 워크로드에 맞는 최소한의 파티션으로 시작하고, 필요에 따라 자동으로 파티션을 늘려나가는 동적인 방식
공식문서: DynamoDB의 글로벌 보조 인덱스도 파티션으로 구성됩니다. 글로벌 보조 인덱스의 데이터는 기본 테이블의 데이터와 별도로 저장되지만, 인덱스 파티션은 테이블 파티션과 거의 동일하게 작동합니다.
- 용어 기준인가? 문서 기준인가?
- AI: DynamoDB 글로벌 보조 인덱스 (GSI)의 파티셔닝 방식은 문서 기준 보조 색인 파티셔닝의 개념에 가장 가깝습니다. 각 GSI 파티션은 데이터의 하위 집합을 담당하고 로컬 색인 역할을 하며, 높은 확장성과 독립적인 성능을 제공합니다.
- DynamoDB도 핫파티셔닝이 발생
- 기본적으로 dynamoDB에서 핫파티션 발생시 Adaptive Capacity가 파티션을 분할시킴 How Amazon DynamoDB adaptive capacity accommodates uneven data access patterns (or, why what you know about DynamoDB might be outdated) | Amazon Web Services
- adaptive capacity가 핫파티션이 발생하면 자동으로 감지하여 파티션 분할해준다. 이후 여러 개의 작은 파티션으로 분산하여 분할된 파티션으로 트래픽을 재분산 시켜주기도 하지만 무한정 확장이 가능한 것은 아님
- DynamoDB 시스템 자체의 물리적인 제약과 사용자가 프로비저닝한 용량 한도 내에서 작용
- 매우 짧은 시간 안에 급격하게 트래픽이 폭증하는 경우 adaptive capacity가 따라가지 못함
- 프로비저닝된 용량 모드를 사용하는 경우, 테이블에 설정된 최대 읽기/쓰기 용량 **한도 내에서 Adaptive Capacity가 작동
- DynamoDB 테이블의 용량 한계에 도달하면 쓰로틀링이 걸리고, 쓰로틀링도 감당할 수 없으면
CapacityExceededException를 반환한다.- 해당 에러는 애플리케이션 예외기 때문에 재시도 로직 같은 것을 애플리케이션에서 구현해야한다.
- DynamoDB 시스템 자체의 물리적인 제약과 사용자가 프로비저닝한 용량 한도 내에서 작용
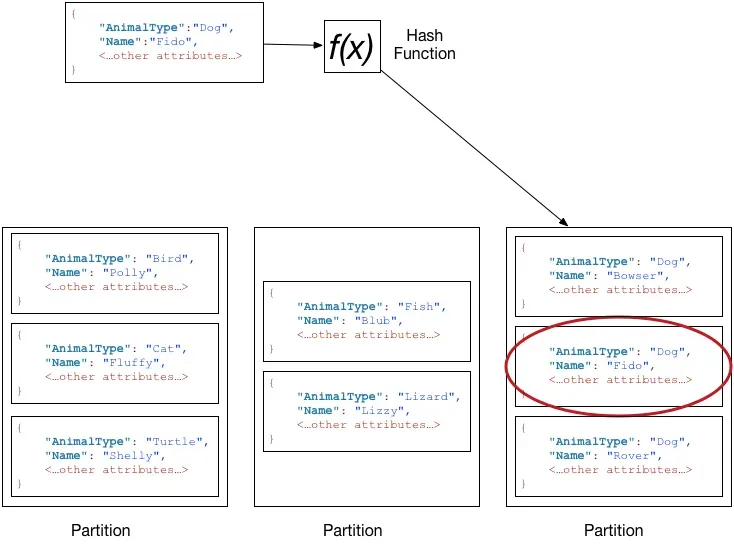
공식문서: 테이블에 항목을 쓰기 위해, DynamoDB는 파티션 키 값을 내부 해시 함수의 입력으로 사용합니다. 해시 함수의 출력 값은 항목이 저장될 파티션을 결정합니다.
- 따라서 같은 파티션에 많은 데이터가 저장되는 것이 예상된다면 해당 방법으로 최대한 피해줘야 함
- 방법: For example, for a partition key that represents today’s date, you might choose a random number between
1and200and concatenate it as a suffix to the date. This yields partition key values like2014-07-09.1,2014-07-09.2, and so on, through2014-07-09.200. Because you are randomizing the partition key, the writes to the table on each day are spread evenly across multiple partitions. This results in better parallelism and higher overall throughput. Using write sharding to distribute workloads evenly in your DynamoDB table - Amazon DynamoDB
- 방법: For example, for a partition key that represents today’s date, you might choose a random number between
- 하지만 이렇게 나눈다면 모든 suffix를 쿼리한 뒤에 수동으로 결과를 합쳐줘야 한다.