Elasticache 클러스터 전환 시도기
현재 Redis가 클러스터 모드가 비활성화 된 채로 읽기 복제본만 존재합니다. 이번에 SSE를 도입하면서 redis pub/sub까지 도입을 해야하기에, redis로 인한 장애를 최소화하고자 클러스터 모드를 도입하는 것을 검토하고 있습니다.
ElastiCache의 클러스터 모드 활성화 비활성화 주요 차이점
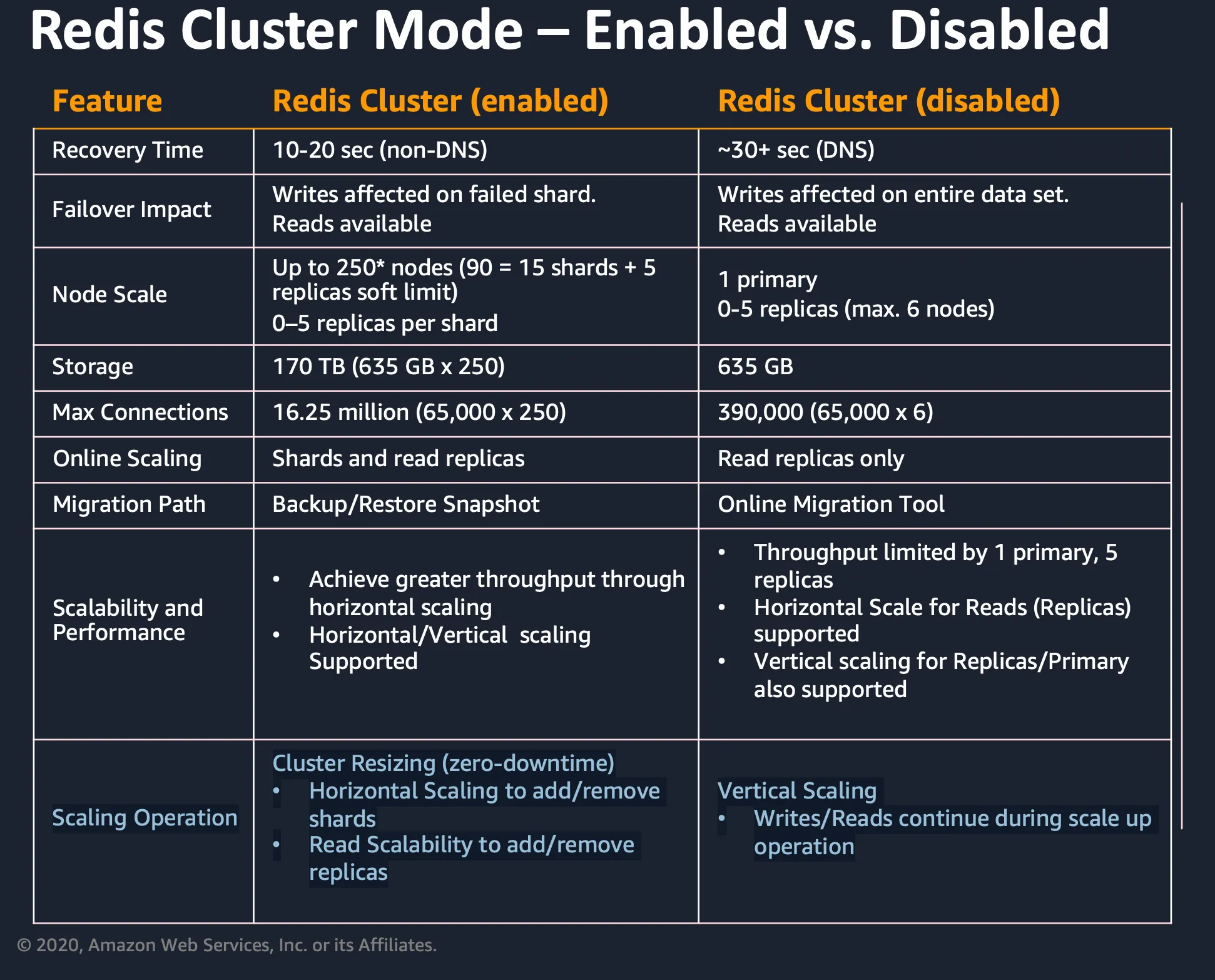
출처: https://pages.awscloud.com/rs/112-TZM-766/images/Session 1 - ElastiCache-DeepDive_v2_rev.pdf
제가 눈여겨본 가장 중요한 차이는 Scaling Operation입니다. Cluster Mode에는 샤드의 수평적 확장과 읽기 복제본 추가의 자동 추가/삭제가 자동화되어있지만, 비활성화시에는 수직 확장 밖에 되지 않습니다.
또한 클러스터 비활성화 모드에서는 읽기 복제본 추가를 위해서는 수동으로 추가를 해줘야하고, DNS 업데이트 유무의 차이가 있어서 활성화일 때 보다 복구 시간이 더 오래 걸립니다.
즉, 클러스터 모드 활성화 상태에서는 읽기 복제본을 자동으로 추가하거나 제거하는 Read Scalability가 지원되어, 읽기 처리량을 유연하게 확장할 수 있기 때문에 단일 노드로 ElastiCache를 사용하더라도 클러스터 모드를 사용하는 것이 유리합니다.
클러스터로 변경할 때 주의점
라이브러리 변경 필요
python의 redis 라이브러리 같은 경우, 클러스터를 사용하면 redis.cluster 로 클라이언트를 초기화해줘야 합니다.
# 1. Import 추가
from redis import Redis, RedisError
from redis.cluster import RedisCluster # 추가
# 2. RedisClient.init 변경, startup_nodes추가
def __init__(self):
self.redis_client = RedisCluster(
startup_nodes=[{"host": settings.redis_host, "port": settings.redis_port}],
decode_responses=True,
skip_full_coverage_check=True,
socket_timeout=0.1,
socket_connect_timeout=0.1
)
self.default_ttl = 3600
또한 이전과 달리 DB 선택이 되지 않기 때문에, DB 별로 중복된 키가 존재했다면 따로 분리를 시켜줘야합니다.
예시) app:prod:1234, celery:prod:1234
지원되지 않는 명령어들
클러스터 모드에서는 MGET, MSET, SCAN와 같은 멀티키 명령어를 사용할 때 주의해야합니다. 두 명령어 모두 한번에 가져오거나 한번에 세팅하는 명령어로 모든 키가 같은 해시 슬롯에 있어야 정상 작동하기 때문입니다.
만약 클러스터 모드에서 이를 무시하고 일부 키가 다른 샤드에 존재한다면 CROSSSLOT 오류가 발생합니다.
이를 방지하기 위해 키 네이밍에 해시 태그({})를 사용해 키를 같은 슬롯으로 묶는 추가적인 설계가 필요합니다.
하지만 저는 클러스터 모드여도 단일 노드로 사용할 것이기 때문에 명령어들은 바꿀 필요가 없을 것 같아요.
클러스터 모드로 전환하지 않은 이유
클러스터 모드로 전환하려다 결국 보류했습니다. AutoScaling을 사용하려면 최소 Large 이상의 인스턴스가 필요한데, 현재 medium을 사용 중이고 CPU와 Memory 여유도 충분한 상태였기 때문입니다. 더 큰 문제는 Celery가 RedisCluster를 지원하지 않는다는 점이었습니다. 클러스터 모드로 전환하려면 Celery 브로커를 별도의 단일 노드 Redis로 분리하거나 SQS, RabbitMQ로 교체해야하는 추가 작업을 했어야 했습니다.
SCAN 명령어 등 클러스터 모드에서 작동하지 않는 명령어들도 꽤 많아서, 이를 전부 수정하려면 작업량이 상당할 것 같아, 결론적으로는 가격이 2배나 차이나는 Large로 올려가면서까지 당장 클러스터링을 할 필요는 없어 보였어요.
대안으로는 이번 SSE 도입 시 Redis Pub/Sub 전용 단일 노드를 새로 띄우고, 나중에 서비스가 커지면 그때 Large로 스케일업하며 오토스케일링을 적용하는 게 나을 것 같습니다. 비록 클러스터 모드로 전환은 못 했지만 클러스터 모드의 차이점을 이해했고, 테스트용 Valkey Cluster를 띄워서 적용해봤기 때문에 추후 마이그레이션 시 수월하게 진행할 수 있을 것 같아요!