home
3. 인덱스 튜닝
테이블 랜덤 엑세스 최소화
테이블 랜덤 엑세스
- 데이터가 아무리 많아도 인덱스를 사용하면 데이터가 금방 조회된다.
- 하지만 대량 데이터를 조회할 때는 table full scan보다 느리다.
인덱스 ROWID는 물리적 주소? 논리적 주소?
- 실행 계획에서
TABLE ACCESS BY INDEX ROWID는 인덱스 스캔 뒤 테이블 엑세스라는 뜻 - 인덱스를 스캔하는 이유 = 소량의 데이터를 인덱스에서 빨리 찾고, 테이블 레코드를 찾아가기 위한 주소값
ROWID를 얻기 위함 - ROWID는 포인터와 비슷하지만 물리적 주소가 아니라 논리적 주소이다.
- ROWID는 포인터(메모리 주소 정보)가 아니기 때문에 디스크 주소 정보를 이용해 해시 알고리즘으로 버퍼 블록을 찾는다.
I/O 메커니즘 복습
- 버퍼캐시를 사용해야 성능이 좋아짐
- 해싱 알고리즘으로 버퍼 헤더를 찾고, 거기서 얻은 포인터로 버퍼 블록을 찾음
- ROWID가 가르키는 테이블 블록을 버퍼캐시에서 먼저 찾고, 없으면 디스크에서 찾는다.
- 즉, 모든 데이터가 캐싱이 되어있어도 무조건 버퍼캐시를 거치고, DBA해싱과 래치 획득과정 반복이 필요
메인메모리 DB의 포인터는 전화번호 인덱스 ROWID는 우편주소
인덱스 클러스터링 팩터(CF)
군집성 계수(CF), 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도- CF가 좋은 컬럼에 생성한 인덱스는 검색 효율이 좋다. 이유는 블록 I/O가 적게 발생하기 때문
버퍼 Pinning이 찾아간 데이트 블록의 포인터를 해제하지 않고 유지하기 때문
인덱스 손익분기점
- Index Range Scan에 의한 테이블 엑세스가 Table Full Scan보다 느려지는 지점을 말한다.
- 그렇다면 왜 느려지는가?
- Table Full Scan은 시퀀셜 엑세스, 하지만 인덱스 ROWID는 랜덤 엑세스 방식
- Table FUll Scan은 Multiblock I/O, 인덱스 ROWID는 Single Block I/O
- CF가 좋으면 손익분기점은 당연히 상승한다.
- 5~20%가 손익분기점 평균인데 이는 겨우 10만건, 많아 봐야 100만 이내 에만 테이블에 적용되는 수치이다.
- 예를 들어 10만건 테이블에서 만 건
- 1000만 건에서 10퍼인 100만 건은 성능이 너무 나빠진다. 조회 건수가 많아질 수록 버퍼 캐시에서 찾을 가능성이 낮아지기 때문
온라인 프로그램 튜닝 VS 배치 프로그램 튜닝
- 온라인 프로그램은 대부분 인덱스를 활용한 NL조인
- 반면 배치 프로그램은 전체를 처리해야되기 때문에 Table Full Scan과 해시 조인이 유리
- 하지만 초대용량은 또 말이 달라서 파티션 활용과 병렬 처리까지 필요
- 성능적인 측면에서만 보면 파티셔닝도 Full Scan을 빠르게 하기 위한 것
인덱스 컬럼 추가
- 테이블 엑세스 최소화를 위해서 가장 일반적으로 사용되는 튜닝 기법은 인덱스에 컬럼을 추가하는 것
- 예를 들어 사원 번호, 직업으로 인덱스가 걸려있는데 쿼리를 다음과 같이 한다면 매우 비효율적인 액세스가 발생한다
SELECT
*
FROM
사원
WHERE
사원 번호 = 30
AND 월급 >= 2000
- 사원 번호와 월급이라는 새로운 인덱스를 추가하면 좋겠지만, 이는 데이터베이스에 부하를 가져옴
- 그래서 기존의 인덱스에 월급 을 인덱스 컬럼에 추가를 한다.
- 인덱스 스캔량은 줄지 않으나, 테이블 랜덤 엑세스 횟수를 줄일 수 있다.
인덱스 구조 테이블
- 인덱스를 이용한 테이블 엑세스가 고비용이니, 랜덤 엑세스가 아예 발생하지 않도록 인덱스 구조를 생성한 것이
Index Organized Table이다. - ROWID를 갖는 인덱스와 달리, 그 자리에 테이블 데이터를 갖는다.
- 즉, 인덱스 리프 블록이 곧 데이터 블록이다.
- 인위적으로 CF를 좋게 만드는 방법 중 하나, 이유는 정렬되어 있기 때문
클러스터 테이블
인덱스 클러스터 테이블
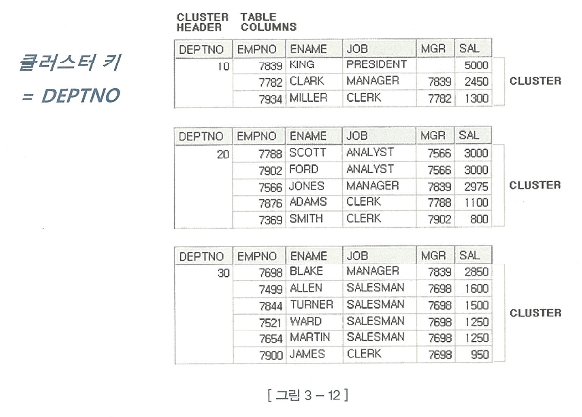
- 클러스터 키값이 같은 레코드를 한 블록에 모아서 저장하는 구조
- 다른 테이블 레코드를 같은 블록에 저장할 수도 있는데 이를
다중 테이블 클러스터라고 한다. - 이는 클러스터형 인덱스와 다른데, 정렬을 하지 않는다.
- 테이블 생성 때, 인덱스를 정의해야되는데, 데이터를 찾는 용도 뿐만 아니라 저장될 위치를 찾을 때도 사용되기 때문
- 클러스터 인덱스는 테이블 레코드의 1:M 관계를 갖는다.
- 해시 클러스터 테이블은 인덱스를 사용하지 않고 해시 알고리즘을 사용한다는 점이 차이점이다.
부분범위 처리 활용
부분범위 처리
- 전체 쿼리 결과집합을 쉼 없이 연속적으로 전송하지 않고 사용자로부터 Fetch Call 이 있을 때마다 일정량씩 나누어 전송하는 것
- 쿼리 결과가 100건일 때, Fetch Call 을 통해서 DB에서 10건을 클라이언트 캐시에 저장
- 그 다음에는 캐시에서 데이터를 읽고, 모두 소진한 상태로 또 부르면 Fetch Call로 10건을 받는다.
- 하지만
ORDER BY에 created 같은 컬럼이 있을 경우, 모든 데이터를 읽어서 정렬을 하고나서야 전송이 가능하다.- 이럴 때, created 컬럼이 선두인 인덱스가 있으면 부분범위 처리 가능
Array Size 조정을 통한 Fetch Call 최소화
- 대량의 데이터를 받으려면 Array Size를 크게 설정 -> Fetch Call을 줄일 수 있다.
- 앞쪽 일부 데이터만 Fetch하다 멈추면 작게 설정
- WAS나 AP 서버 등이 존재하는 n-Tier 아키텍처에는 클라이언트가 특정 DB 커넥션을 독점하지 못한다.
- 하나의 커넥션 풀에서 SQL 조회 결과를 모두 전송하고 커서를 닫아야 함
- 5장 3절에서 n-Tier 부분범위 처리 설명
OLTP 환경에서 부분범위 처리에 의한 성능개선 원리
- 인덱스와 부분범위 처리 원리를 활용하면 OLTP 환경에서 극적인 성능개선 효과를 얻을 수 있다.
SELECT
게시글 ID, 제목, 작성자, 등록일시
FROM
게시판
WHERE
게시판구분코드 = 'A'
ORDER BY
등록일시 desc
- 여기서
게시판구분코드+등록일시로 조합된 인덱스가 존재하지 않으면 sort 연산을 건너띌 수 없다. - 만약 해당 조합으로 인덱스를 생성하면 Sort 연산 생략이 가능하다.
배치 I/O
- 오라클에서 만든 기능
- 원래는 인덱스를 활용해서 테이블을 엑세스하다가 버퍼 캐시에서 블록을 찾지 못하면 디스크 블록에서 바로 읽음
- 근데 이 기능을 활성화하면 테이블 블록에 대한 디스크 I/O Call을 미뤘다가 일정량 쌓이면 한번의 처리
- 버퍼 적중률이 100퍼가 아니면 인덱스 정렬 순서와 다를 수 있다.
- 그래서 필요한 Order By를 생략한 SQL은 문제가 될 수 있음