[칼럼] redis nx로 경쟁 상태 제어하기
중복 데이터 생성에 대한 고분분투기에 대해서 공유드립니다.
안심 결제와 정산 데이터
저희 서비스에는 안심결제라는 결제수단이 존재합니다. 안심결제를 결제 수단으로 상품을 구매를 하면 두 가지, 혹은 한 가지의 정산데이터가 생성됩니다.
하나는 판매자의 전체 정산을 관리하는 판매자 정산 데이터이고, 다른 하나는 각 상품별 정산 정보를 담고 있는 개별 상품 정산 데이터입니다. 이 두 데이터는 1:N 관계를 가지고 있어, 하나의 판매자 정산 데이터에 여러 개의 상품 정산 데이터가 연결될 수 있습니다.
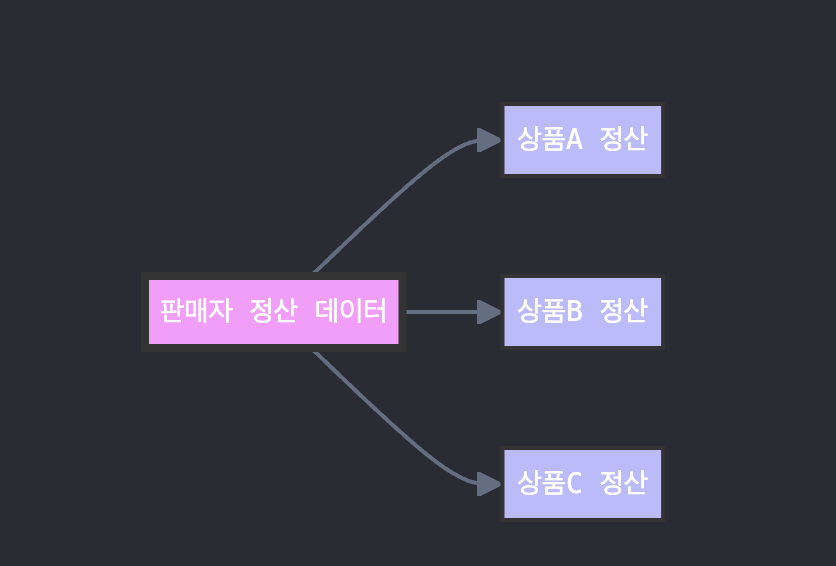
앞서 상품 결제시 생성되는 데이터가 ‘두 가지, 혹은 한 가지’ 라고 한 이유는 다음과 같습니다. 구매자가 안심결제로 상품을 구매할 때 먼저 판매자 정산 데이터가 생성됩니다. 이후 구매한 각각의 상품에 대해 개별 상품 정산 데이터가 생성되며, 해당 상품에 대한 판매자 정산 데이터의 총액이 자동으로 업데이트됩니다.
중요한 점은 해당 상품에 대한 pending 상태의 판매자 정산 데이터가 남아있으면, 다음 구매 발생시 재생성되지 않는다는 점입니다. 즉, 판매자가 정산을 받지 않는다면 상품 하나당 판매자 정산 데이터는 오직 한 개로 존재합니다.
여기서 문제가 발생합니다. 만약 해당 상품이 인기가 엄청나서 구매 즉시 결제가 동시에 많이 일어나는 상품이라면, 판매자 정산 데이터가 여러 건 생성이 된다는 것입니다.
이유는 간단합니다. 기존 코드에 결제가 동시에 발생할 때를 대비한 경쟁 상태를 제어하는 로직이 존재하지 않기 때문입니다. 판매자 정산 데이터가 없는 상태에서 0.01초 간격으로 결제가 동시에 발생하면, pending 상태인 판매자 정산 데이터가 없다고 간주하여 여러 건이 생성되는 것입니다.
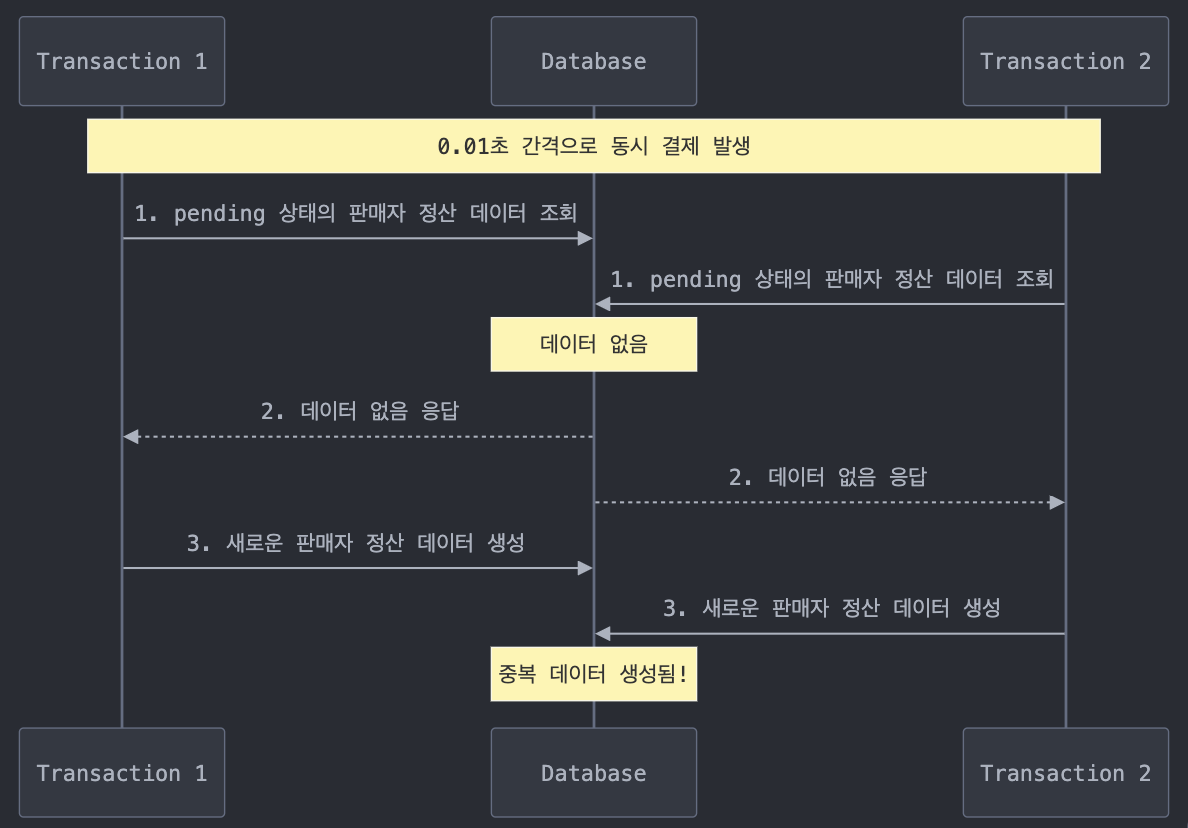
만약 이런 일이 발생하게 되면, 판매자는 정산 페이지에서 같은 상품에 대해 여러 건의 정산 데이터가 생성된 것을 보게되는 당황스러운 일이 발생합니다.
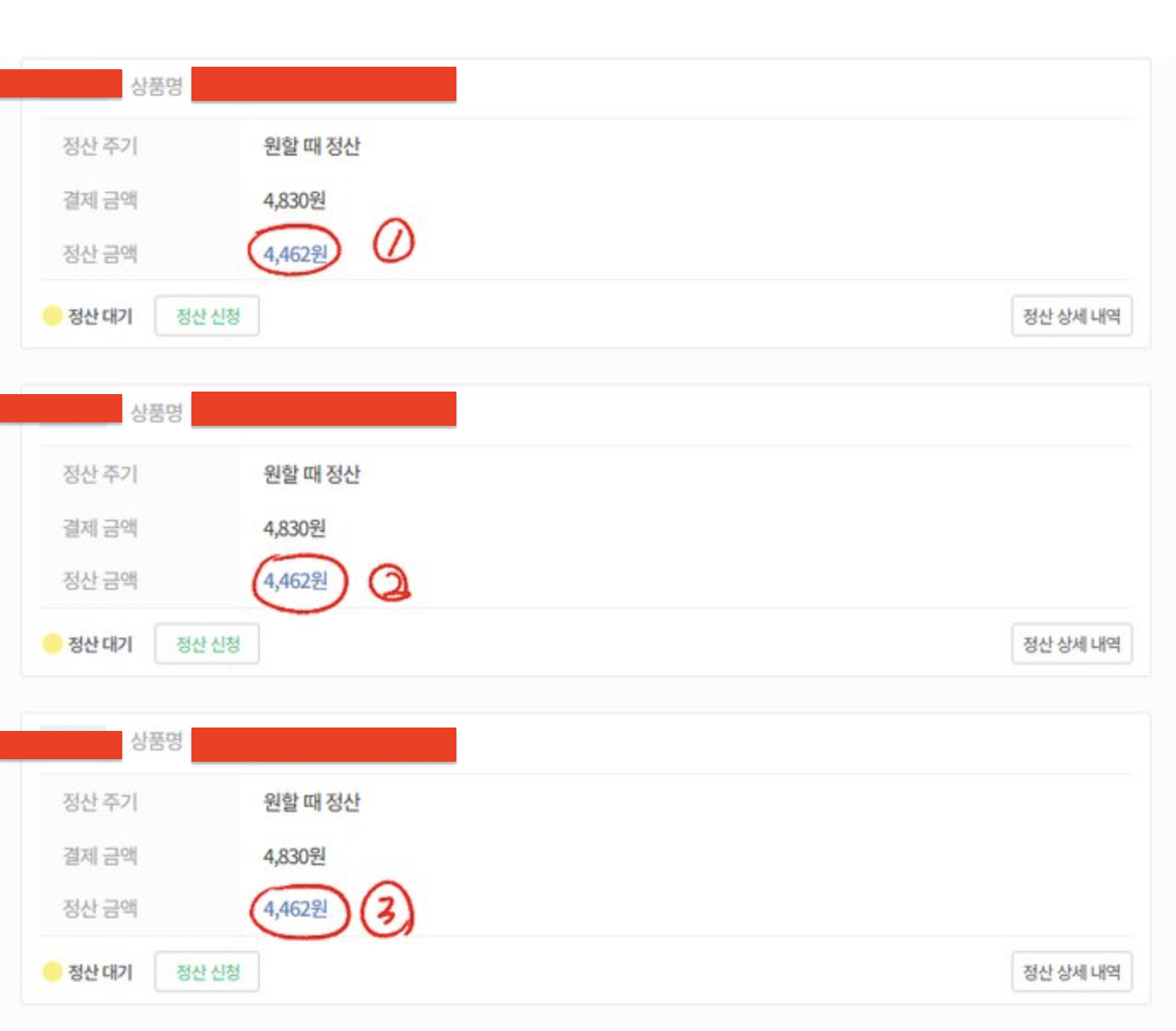
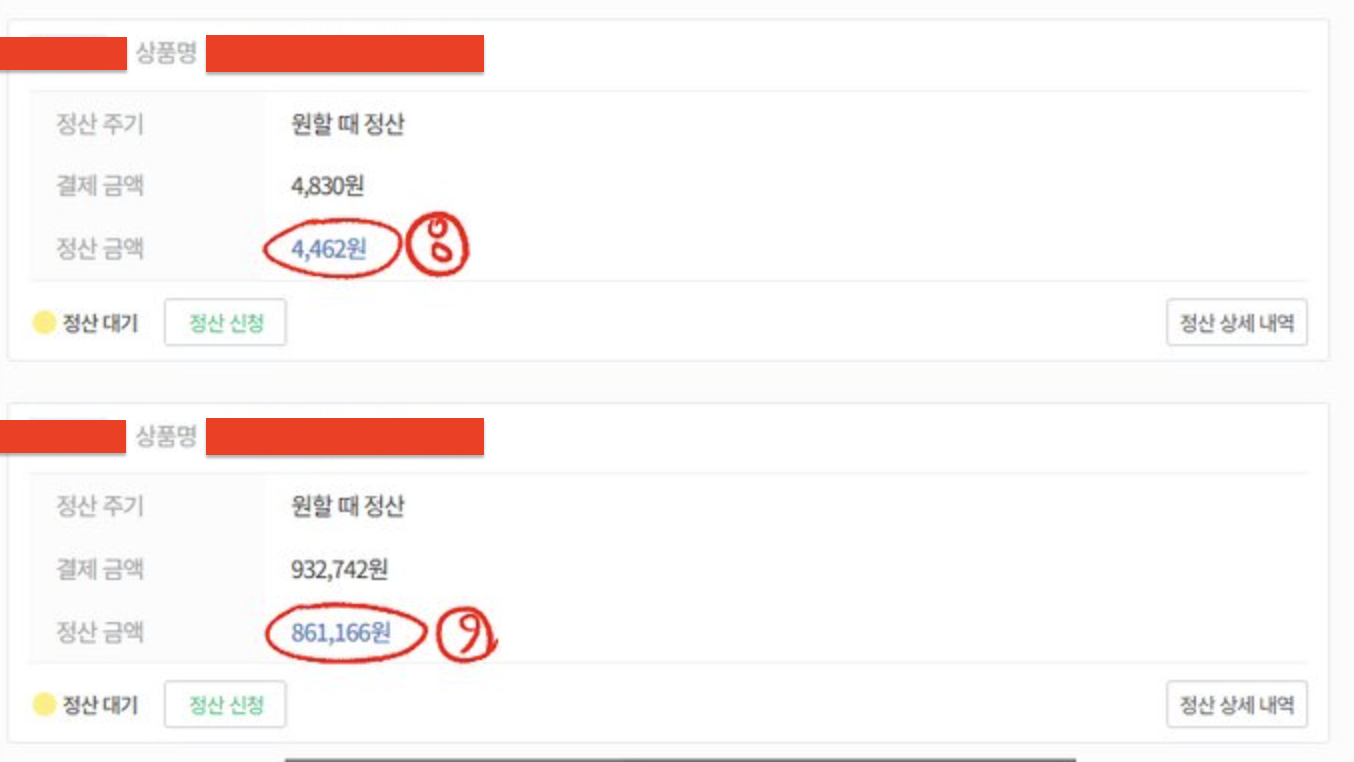
이와 같은 일이 발생하면 아주 번거로운 일이 발생합니다. 우선 운영팀이 CS를 받아서 백엔드팀에게 데이터 수정을 요청하고, 백엔드 팀은 여러 개의 판매자 정산 데이터를 하나로 만든 뒤 개별 상품 정산 데이터의 금액을 모두 합하여 총 정산 데이터를 업데이트 해줍니다.
만약 조금의 실수가 있으면 판매자에게 더 높은 금액으로 정산이 되거나, 덜 되거나 하는 아찔한 상황이 벌어지기 때문에, 해당 CS가 들어오면 운영팀과 개발팀 모두 큰 힘을 쏟아 처리해야 했습니다.
때문에 이를 해결하기 위해서 다음과 같은 몇 가지 방법을 시도해보았습니다.
고분 분투의 흔적
비관적 락
간단하게 SELECT FOR UPDATE 를 활용하는 방법입니다. 결제가 발생할 때, 판매자 정산 데이터가 존재하는지 여부를 알려주는 쿼리에 이를 적용하는 것 입니다. Repeatable Read의 데이터베이스 격리수준에서는 다른 트랜잭션에서 데이터가 변경되어도 트랜잭션이 종료되기 전까지는 트랜잭션이 시작할 때의 스냅샷을 보게됩니다. 이런 상태에서, 다른 트랜잭션에서 변경한 최신 데이터를 보기 위한 방법 중 하나가 SELECT FOR UPDATE 를 사용하는 것 입니다. 이에 대한 내용은 전에 정리한 내용이 있어 자세한 설명은 건너 띄겠습니다.
해당 방법은 간단하나, 성능 저하와 데드락의 위험성은 늘 존재합니다. 여러 결제 건 발생 시, 한 개의 판매자 정산데이터에 개별 상품 정산 데이터의 가격들을 UPDATE 해줘야 하기 때문에 교착 상태가 발생하기 쉬워 해당 방법은 택하지 않았습니다.
분산락
redis를 활용한 분산락을 활용하여 판매자 정산 데이터 생성을 제어해보는 방법도 구현해보았습니다.
def acquire(self, key: str, timeout: int = 5, retry_delay: Optional[float] = None, max_retries: Optional[int] = None) -> bool:
retries = max_retries or self.max_retries
delay = retry_delay or self.retry_delay
try:
for attempt in range(retries):
is_set = bool(self.redis_client.set(f"lock:{key}", "1", nx=True, ex=timeout))
if is_set:
return True
time.sleep(delay)
return False
except RedisError as e:
...
return False
다음과 같이 set메소드의 nx 를 활용하여 같은 키가 존재하지 않을 때만 set이 가능하게 하고, set을 성공하면 True를 반환해주는 Redis Client를 생성합니다. nx 옵션을 True 로 만들어주면, 동일 키가 존재하지 않을 때만 set이 가능합니다.
이것을 판매자 정산 데이터가 생성되는 로직에 적용해봅시다. 먼저 락을 얻은 첫번째 요청은 판매자 정산 데이터를 만들게 되고, 그 동안 두번째 결제 요청은 락을 얻기 위해 대기를 하게 됩니다.
이후 첫번째 요청이 판매자 정산 데이터를 만들게 되면 락이 풀리게 되고, 그 다음 요청이 락을 얻게 됩니다. 앞의 요청에서 판매자 정산 데이터가 만들어졌으니 이미 생성된 판매자 정산 데이터를 활용하여 업데이트만 수행해주어 중복 데이터가 생성되지 않도록 설계했습니다.
하지만 문제점이 발생했는데, 분산락 또한 데이터베이스 격리수준에서 자유롭지 못했다는 것입니다.
후의 요청이 락을 얻었다고 하더라도 트랜잭션이 시작할 때의 스냅샷 데이터를 읽게 되기 때문에, 두번째 요청에서는 첫번째 요청에서 insert 후 commit 한 판매자 정산 데이터를 읽어오지 못하게 합니다.
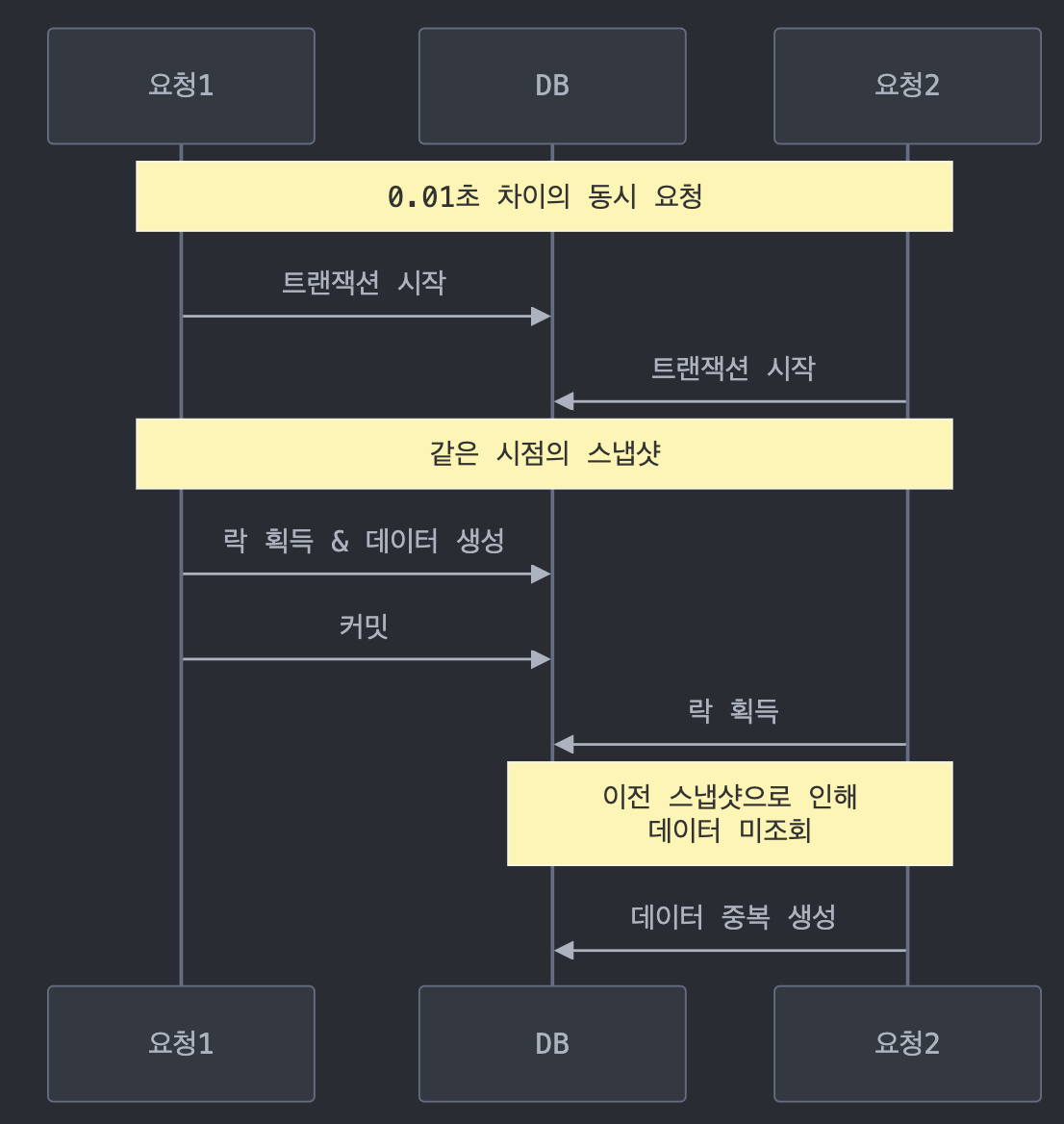
이를 해결하기 위해 몇 가지 해결 방법을 모색했습니다.
1. 트랜잭션 종료 후 다시 시작
이는 다음과 같이 구현할 수 있습니다.
# ... 락 획득 로직
db.commit()
db.begin() # sqlalchemy에서는 commit() 이후에 자동으로 트랜잭션이 시작하기 때문에
# 굳이 선언하지 않아도 됩니다.
# 이후 판매자 정산 데이터를 조회하고, 없으면 생성하는 로직
이렇게 commit() 을 통해서 트랜잭션을 종료시키고, 새로운 트랜잭션을 시작하면 첫번째 요청에서 업데이트한 최신의 데이터를 읽어올 수 있게 됩니다.
하지만 문제점은 db.commit()을 호출하기 전에 현재 트랜잭션에 변경사항이 있다면 그것들도 함께 커밋하게 되어 데이터의 정합성 문제가 생길 수 있습니다. 또한 새로운 트랜잭션이 시작되는 것이기 때문에, 이전 트랜잭션의 컨텍스트가 잃게 되어 예상치 못한 동작들이 발생할 수 있습니다.
2. 새로운 DB Connection 연결
말 그대로 판매자 정산 데이터를 조회하고 없으면 생성하는 로직 앞에, 새로운 db connection을 생성하여 최신의 데이터만을 읽기 위한 트랜잭션을 여는 방법입니다. 이렇게 되면 앞의 방법처럼 기존의 트랜잭션 컨텍스트를 헤치지 않고 최신의 데이터를 읽어올 수 있습니다.
하지만 만약 결제 건이 100건, 1000건이 동시에 발생한다면 그만큼 새로운 db connection이 발생하게 될 것이고, 이는 곧바로 DB 부하로 이어지기 때문에 문제점이 있습니다.
즉, 분산락을 사용하더라도 최신의 데이터를 읽기 위해서는 SELECT FOR UPDATE 를 사용해야 한다는 결론에 도달하게 됩니다. 따라서 저는 열심히 구현을 끝 마친 분산락을 과감히 포기하고 다른 방법을 모색하였습니다.
최종으로 택한 redis의 nx 활용법
앞서 말했듯이, redis의 set 메서드에는 nx 라는 옵션이 존재합니다. 이를 활용하면 분산락을 사용하지 않고도 중복 데이터 생성을 방지할 수 있게 됩니다. 원리는 간단합니다.
우선 결제 요청이 들어오면 판매자 정산 데이터가 존재하는지 확인합니다. 만약에 존재한다면 그대로 해당 판매자 정산 데이터를 활용하고, 존재하지 않는다면 다음과 같은 로직을 수행합니다.
with db.begin_nested():
생성된_판매자_정산_데이터_id: int = repository.판매자_정산_데이터_삽입_로직(data)
set_성공_여부: bool = redis_client.set(key=key, value=생성된_판매자_정산_데이터_id, nx=True)
if not set_성공_여부:
판매자_정산_데이터_id = int(redis_client.get(key=key))
db.rollback()
새로 생성된 ‘판매자_정산_데이터_id’를 값으로 설정한 채로 set 메서드의 nx 을 True로 설정합니다. 이렇게 되면 set이 성공하면 True, 실패한다면 False를 뱉습니다.
만약 False를 반환한다면, 앞선 요청이 먼저 판매자 정산 데이터를 만들고 redis에 set을 진행한 것으로, 해당 키를 다시 조회해 앞선 요청이 설정한 판매자 정산 데이터 id를 얻어 옵니다. 그리고 본인이 만든 판매자 정산 데이터는 다시 rollback() 시킵니다.
이렇게 얻은 판매자 정산 데이터 id로 개별 상품 정산 데이터를 만들어주면 중복 없이 올바른 데이터들이 생성됩니다.
이렇게 복잡한 기술을 사용하지 않고도 redis 만으로 경쟁 상태를 제어하여 중복 데이터 생성을 막게 되었습니다. 백엔드 팀도, 운영팀도 모두 행복해졌네요. 이 글이 누군가에게는 도움이 되었으면 좋겠습니다. 감사합니다.