Firebase python sdk 트러블 슈팅기
문제 발생
FCM 전송 서버에서 일어난 일을 정리해보았습니다. 개발이 대략적으로 마쳐서 어제 처음으로 800명한테 보내보았는데, 발송은 잘 되었으나 다음과 같이 무시무시하게 경고를 하고 있었습니다.
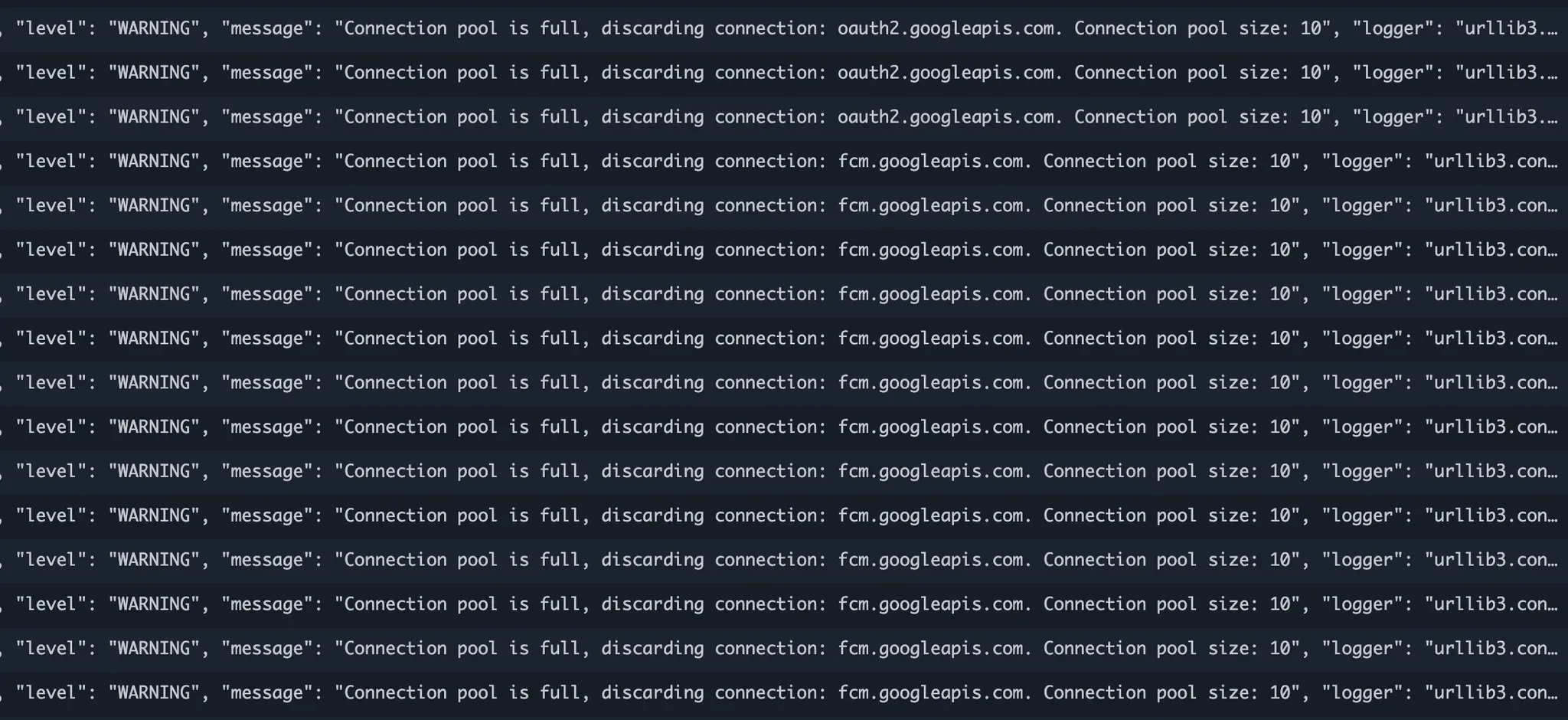
메시지 하나를 자세하게 보면 다음과 같이 경고를 하고 있었습니다.
{
"timestamp": "2025-01-17T10:00:49Z",
"level": "WARNING",
"message": "Connection pool is full, discarding connection: fcm.googleapis.com. Connection pool size: 10",
"logger": "urllib3.connectionpool",
"requestId": "f2a8d6f7-a1ac-5e1e-b308-b6f38dd94612"
}
대충 의미를 보면 python코드에서 Post나 Get request를 할 수 있게 해주는 urllib3 이라는 라이브러리에서 발생한 경고인데 해석해보면 다음과 같습니다.
- 연결 풀(Connection pool)이 가득 찼다. 현재 연결 풀 크기가 10으로 설정되어 있고 이 제한에 도달했다.
- fcm.googleapis.com에 대한 새로운 연결 시도가 있었지만, 풀이 가득 차 있어서 이 연결이 버려졌다.
처음 이 경고를 보았을 때는 이해하기 어려웠습니다. FCM의 멀티캐스트 메시지는 한 번에 최대 500개까지 전송할 수 있다는 제한이 있기에, 저는 이미 메시지를 적절한 크기로 나누어 처리하고 있었습니다.
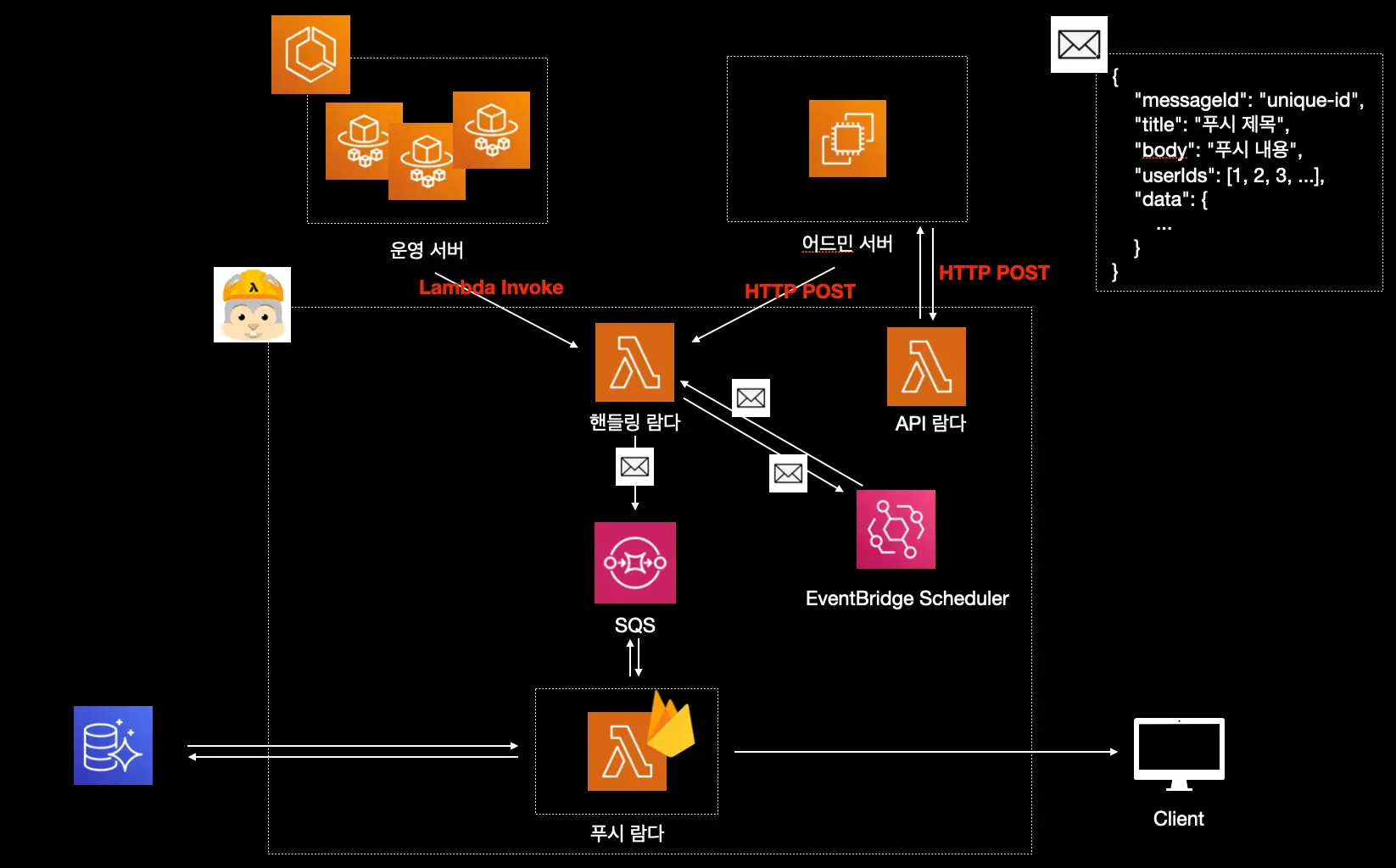
위가 현재 개발 중인 아키텍처입니다. 500명 이상의 사용자에게 알림을 전송해야 하는 상황에 대응하도록 설계되었습니다. 먼저 핸들링 람다가 메시지를 수신하면, 수신자가 500명을 초과할 경우 이를 50명 단위로 분할하여 새로운 메시지들을 생성합니다. 이 메시지들은 SQS로 전송되며, 푸시 람다는 이러한 메시지들을 자동으로 스케일링하며 병렬적으로 처리합니다. (물론 메시지 하나당 하나의 람다가 생기는 건 아닙니다. batch size와 같은 고려 요소가 존재하기 때문입니다.)
푸시 람다는 50개의 user_id가 포함된 메시지를 받으면, 해당하는 FCM 토큰들을 조회합니다. 대략 40-60개 정도의 토큰을 조회 후 이 토큰들을 사용하여 푸시 알림을 전송합니다.
이렇게 하면 문제 없이 안정적으로 동작할 것이라 생각했는데, 갑자기 커넥션 풀 에러가 발생하여 의아했습니다. 혹시 처음부터 한 번에 10개씩만 전송하라는 권장사항이 있었던 걸까요?
그래서 검색을 좀 해보았는데 밑과 같은 이슈가 있었습니다.
저만 겪는 문제가 아니었어요! 특정 버전에서 connection pool 에러가 발생한다고 합니다. 눈여겨 보았던 것은 FCM의 멀티캐스트 메시지가 실제로는 개별 메시지로 전송된다는 것 이었습니다. 이 동작을 확인하기 위해 소스코드를 직접 살펴보기로 했습니다.
소스코드 분석
def send_each(messages, dry_run=False, app=None):
"""Sends each message in the given list via Firebase Cloud Messaging.
If the ``dry_run`` mode is enabled, the message will not be actually delivered to the
recipients. Instead FCM performs all the usual validations, and emulates the send operation.
Args:
messages: A list of ``messaging.Message`` instances.
dry_run: A boolean indicating whether to run the operation in dry run mode (optional).
app: An App instance (optional).
Returns:
BatchResponse: A ``messaging.BatchResponse`` instance.
Raises:
FirebaseError: If an error occurs while sending the message to the FCM service.
ValueError: If the input arguments are invalid.
"""
return _get_messaging_service(app).send_each(messages, dry_run)
기존의 send_all이나 현재의 send_each_for_multicast()와 같은 메서드들은 모두 SDK 내부적의 send_each() 메서드를 호출하도록 구현되어 있었습니다.
def send_each(self, messages, dry_run=False):
"""Sends the given messages to FCM via the FCM v1 API."""
if not isinstance(messages, list):
raise ValueError('messages must be a list of messaging.Message instances.')
if len(messages) > 500:
raise ValueError('messages must not contain more than 500 elements.')
def send_data(data):
try:
resp = self._client.body(
'post',
url=self._fcm_url,
headers=self._fcm_headers,
json=data)
except requests.exceptions.RequestException as exception:
return SendResponse(resp=None, exception=self._handle_fcm_error(exception))
else:
return SendResponse(resp, exception=None)
message_data = [self._message_data(message, dry_run) for message in messages]
try:
with concurrent.futures.ThreadPoolExecutor(max_workers=len(message_data)) as executor:
responses = [resp for resp in executor.map(send_data, message_data)]
return BatchResponse(responses)
except Exception as error:
raise exceptions.UnknownError(
message='Unknown error while making remote service calls: {0}'.format(error),
cause=error)
그래서 더 깊게 들어가보면 send_data라는 내부 함수가 클로저 형태로 정의되어 있었는데, 여기서 가장 주목해야 할 부분은 ThreadPoolExecutor의 사용 방식이었습니다.
with concurrent.futures.ThreadPoolExecutor(max_workers=len(message_data)) as executor:
responses = [resp for resp in executor.map(send_data, message_data)]
return BatchResponse(responses)
GitHub 이슈의 내용이 정확했습니다. 라이브러리는 예상과 달리 메시지들을 하나의 요청으로 모아서 보내지 않고, 각 메시지마다 별도의 스레드를 생성하여 개별적으로 요청을 보내고 있었습니다. ThreadPoolExecutor가 메시지 개수만큼의 스레드를 생성하고, 각 스레드에서 send_data를 호출하는 방식입니다.
requests 라이브러리의 기본 connection pool 크기가 10인데 반해 50개의 스레드가 동시에 요청을 보내고 있었으니 당연히 connection pool이 한계에 도달할 수밖에 없었습니다.
for i in range(0, len(messages), batch_size):
batch = messages[i:i+batch_size]
response = messaging.send_each(batch)
connection pool의 크기를 늘리는 방안도 고려했지만 대신 더 안전한 해결책을 선택했습니다. 메시지를 적절한 batch_size로 나누어 순차적으로 send_each를 호출하는 방식으로 변경했더니, 경고 메시지 없이 정상적으로 작동하게 되었습니다.
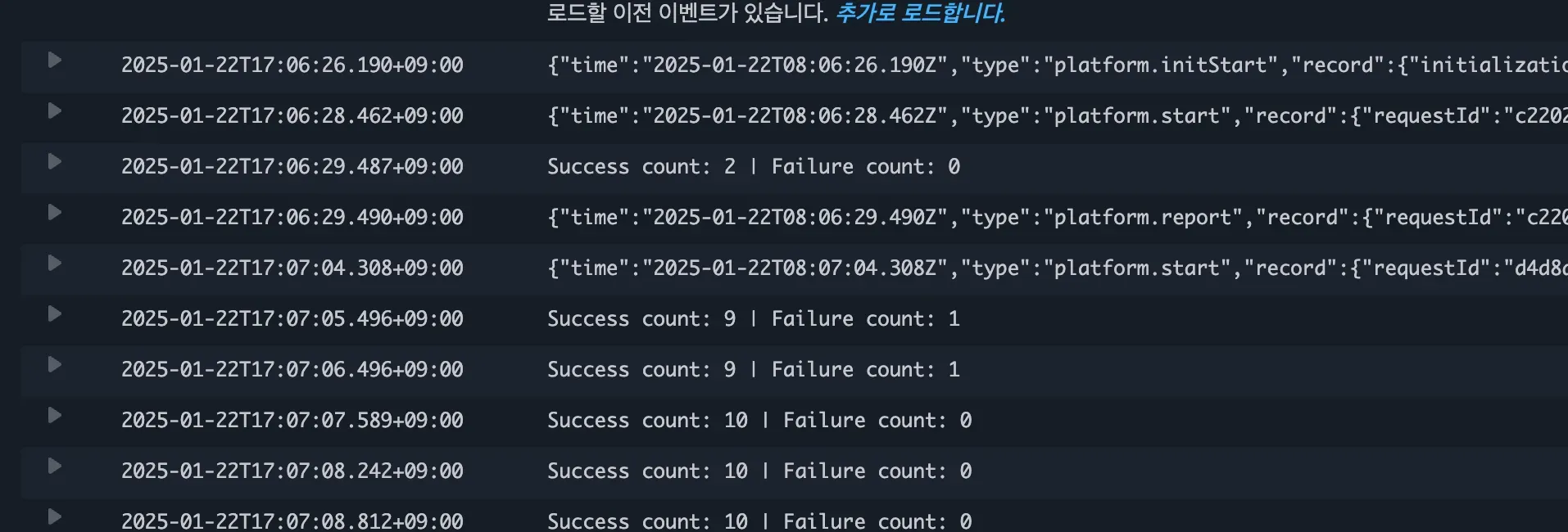
기존의 테이블을 큐로 사용하여 5분에 한번씩 크론을 도는 방식에서 알림서버를 람다로 옮기니 매우 안정적이고 빠른 속도로 메시지를 전송할 수 있게 되었습니다. 해당 서버에 대한 포스팅은 이후에 완성되고 운영 후 공유드리겠습니다.