Validator가 data access layer에 의존해도 되는가?
어떤 상품에 주문서를 제출했는지(is_submitted)를 확인하는 로직이 필요했습니다. 상품, 티켓, 부스 등 다양한 상품 종류가 있었고, is_submitted를 활용해야 하는 로직이 너무 많아 validator 객체를 만들어 관리하고자 했습니다.
대부분의 경우 아래와 같은 쿼리를 통해 is_submitted 여부를 확인합니다.
SELECT EXISTS(
SELECT
1
FROM
ticket_form
WHERE
ticket_id = :ticket_id
AND deleted_date is null
) as is_exists
validator에 데이터 접근 로직을 넣어 이런 쿼리를 실행한다면 서비스 레이어에서의 코드 중복을 줄일 수 있을 것이라 판단했습니다. 다만, Repository를 직접 의존하기보다 중간 레이어를 두는 것이 더 나은 설계라고 생각했습니다. 그 이유는 다음과 같습니다.
- validator는 상품, 티켓, 부스, 티켓 폼 등 다양한 도메인을 조회해야 하는 로직이 많습니다. BoothRepository, ProductRepository 등 여러 Repository에 대한 의존성을 하나씩 추가하다 보면 객체가 너무 무거워질 우려가 있었습니다.
- validator는 다른 도메인 로직이나 서비스 로직과 동일한 레이어에 위치하지만, 위와 같은 이유로 조금은 다른 성격을 가진 객체라고 판단했습니다.
이러한 문제를 해결하기 위해 두 가지 방안을 고려했습니다.
1안: 인터페이스를 통한 의존성 역전 원칙(DIP) 적용
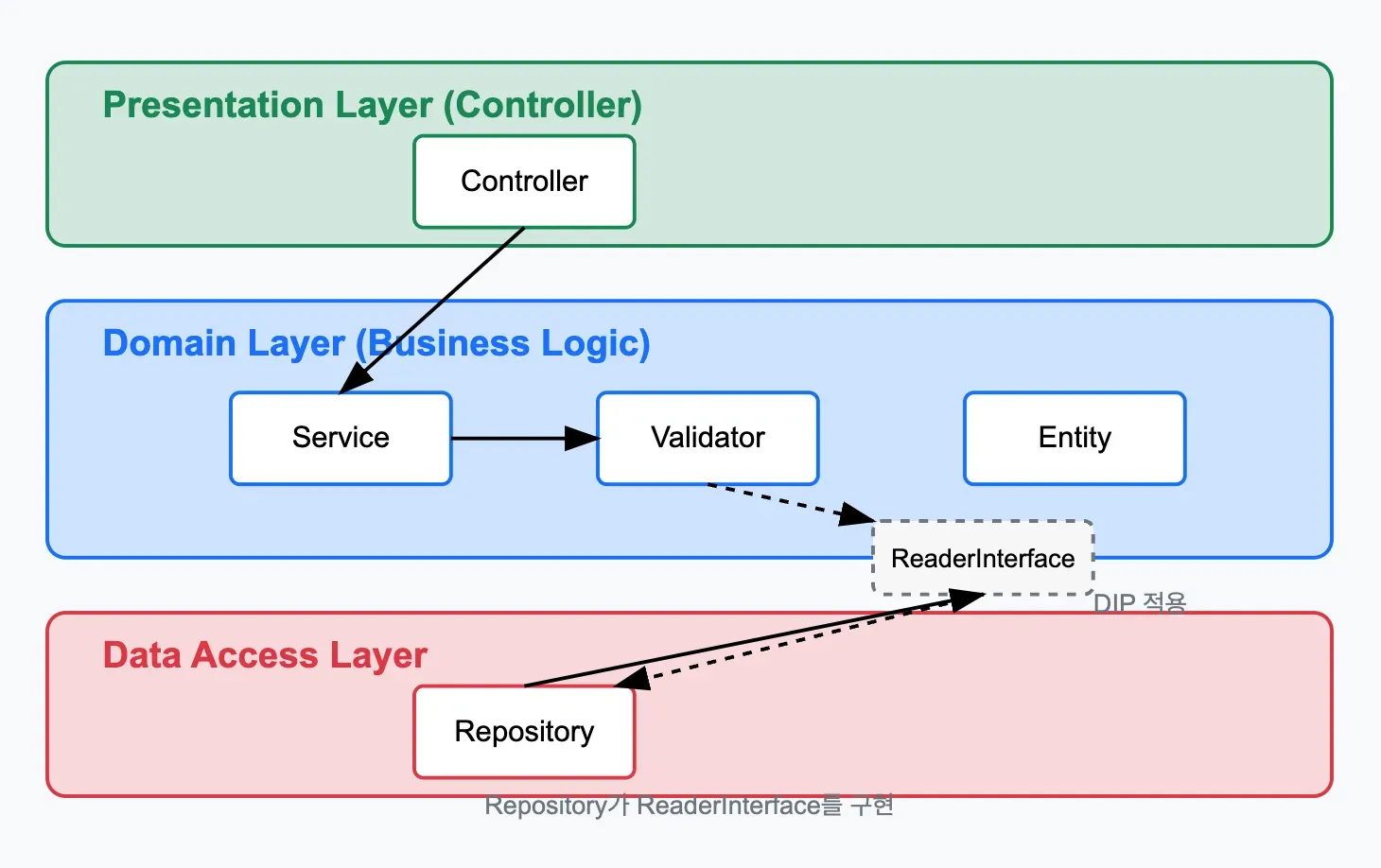
의존성 역전 원칙(Dependency Inversion Principle)은 SOLID 원칙 중 하나로, 고수준 모듈이 저수준 모듈에 직접 의존하지 않고 추상화에 의존해야 한다는 원칙입니다.
이 방안에서는 Validator가 ReaderInterface라는 추상화에 의존합니다. 실제 Repository 구현체는 이 인터페이스를 구현하여, 고수준 모듈(Validator)이 저수준 모듈(Repository)에 직접 의존하지 않도록 합니다. 이렇게 하면 validator는 데이터 접근 계층에 직접 의존하지 않으면서도 필요한 검증을 수행할 수 있습니다.
다만 이 방식의 트레이드오프는 해당 Reader 구현체가 여러 도메인의 데이터 접근 로직들을 한데 모아 ‘신의 객체(God Object)’가 될 가능성이 있다는 점입니다. 신의 객체란 너무 많은 책임과 기능을 가진 객체로, 유지보수와 테스트가 어려워질 수 있습니다.
2안: Facade 패턴을 활용한 중간 레이어 도입
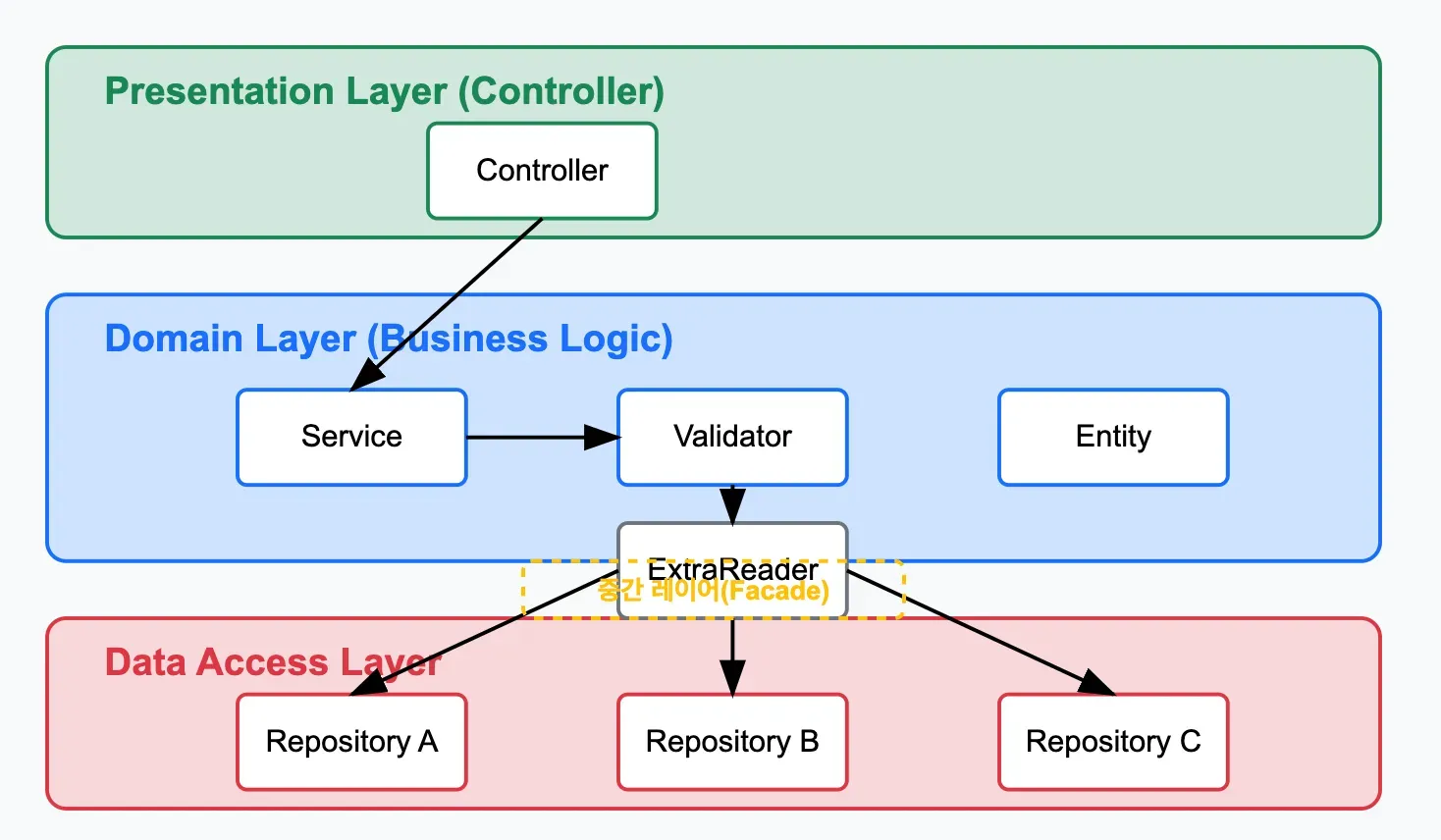
Facade 패턴은 복잡한 서브시스템에 대한 단순화된 인터페이스를 제공하는 디자인 패턴입니다.
이 방안에서는 validator가 Reader를 직접 의존하되, 이 Reader는 직접적인 데이터 접근 로직을 포함하지 않고 다른 Repository들을 의존하여 데이터 접근 로직을 추상화하고 조합합니다. Reader는 Facade 패턴을 구현하여 도메인 레이어와 데이터 접근 레이어 사이의 중간 계층 역할을 합니다.
이 방식의 장점은 Reader가 1안처럼 다양한 도메인 데이터에 직접 접근하지 않아도 되고, 기존 Repository 로직들을 효율적으로 활용할 수 있다는 것입니다. 단점으로는 Reader 객체에 너무 많은 Repository 의존성이 추가될 수 있다는 점이 있습니다.
첫 번째 결정
처음에는 첫 번째 방안을 선택했습니다. 여러 도메인에 걸친 검증 로직을 한 곳에서 관리하는 것이 유지보수 측면에서 더 효율적이라고 판단했기 때문입니다.
구현 예시는 다음과 같습니다.
# 추상 인터페이스 정의
from abc import ABC, abstractmethod
class EventReaderInterface(ABC):
@abstractmethod
def existBoothRegisterByEventId(self, event_id: int) -> bool:
pass
@abstractmethod
def existTicketByEventId(self, event_id: int) -> bool:
pass
# 기타 필요한 추상 메서드들...
# Validator가 구체 클래스가 아닌 인터페이스에 의존하도록 설정
class EventValidator:
def __init__(self, reader: EventReaderInterface):
self._reader = reader
# 검증 로직 구현...
이 방식을 통해 validator가 데이터 접근 레이어에 직접 의존하는 것을 피할 수 있고, 테스트 시에도 Reader 객체만 Mocking 해주면 되기 때문에 유지보수성을 높일 수 있었습니다.
리팩토링
하지만 이 코드를 실제로 사용하면서 몇 가지 문제점이 드러났습니다.
과연 모든 검증 로직이 이렇게 추상화되어야 하는가?
인터페이스 하나에 하나의 구현체만 존재하는 형태가 많아지면서, 오히려 복잡도가 증가하는 오버엔지니어링이 아닌가 하는 고민이 생겼습니다. 불필요한 추상화는 코드를 이해하기 어렵게 만들 수 있습니다.
이러한 문제점을 해결하기 위해 추상화된 인터페이스를 통한 데이터 접근 로직 추상화보다는 2안이었던 Facade 패턴을 활용한 중간 레이어로 리팩토링을 진행했습니다.
1안의 단점에 비해 2안의 단점은 많은 레포지토리를 의존하다뿐이었기에 더 나은 설계라고 생각했습니다.
class ExtraReader:
def __init__(self, event_repository: EventRepository, ticket_repository: TicketRepository, booth_repository: BoothRepository):
self._event_repository = event_repository
self._ticket_repository = ticket_repository
self._booth_repository = booth_repository
# 필요한 다른 repository들...
def read_event_by_id(self, event_id: int) -> Event:
event: Event = self._event_repository.get_event_by_id(event_id)
return event
def read_ticket_by_id(self, ticket_id: int) -> Ticket:
# 티켓 조회 로직...
class EventValidator:
def __init__(self, reader: ExtraReader):
self._reader = reader
# 검증 로직 구현...
이렇게 추상화된 인터페이스 대신 Facade 패턴을 활용한 중간 레이어를 도입함으로써 기존의 데이터 접근 로직을 효과적으로 재사용하면서도 코드의 복잡도를 관리할 수 있었습니다. 이 접근 방식은 불필요한 추상화를 줄이고 실용적인 설계를 하는게 가능했습니다.
결론
데이터 접근 계층에 의존하는 Validator를 설계할 때, 인터페이스를 통한 DIP 적용과 Facade 패턴 중 어느 것이 더 적합한지는 프로젝트의 크기, 복잡성, 그리고 팀의 선호도에 따라 달라질 수 있습니다.
중요한 것은 추상화의 수준을 적절히 조절하여 코드의 유지보수성과 이해도를 높이는 것입니다. 때로는 과도한 추상화보다 실용적인 접근 방식이 더 효과적일 수 있습니다.
좋은 소프트웨어 설계란 이론적 원칙과 실용성 사이의 균형을 찾는 과정이라고 생각하면서 이번 아티클을 마무리하겠습니다. 😁